The Content Viewer area is in the lower right area of the interface. This area is used to view a specific file in a variety of formats. There are different tabs for different viewers. Not all tabs support all file types, so only some of them will be enabled. To display data in this area, a file must be selected from the Result Viewer window.
The Content Viewer area is part of a plug-in framework. You can install modules that will add more viewer types. This section describes the viewers that come by default with Autopsy.
Here's an example of a "Content Viewer" window:

Default Viewers Currently, there are 5 main tabs on "Content Viewer" window:
- Result Content Viewer
- Hex Content Viewer
- String Content Viewer
- Media Content Viewer
- Text Content Viewer
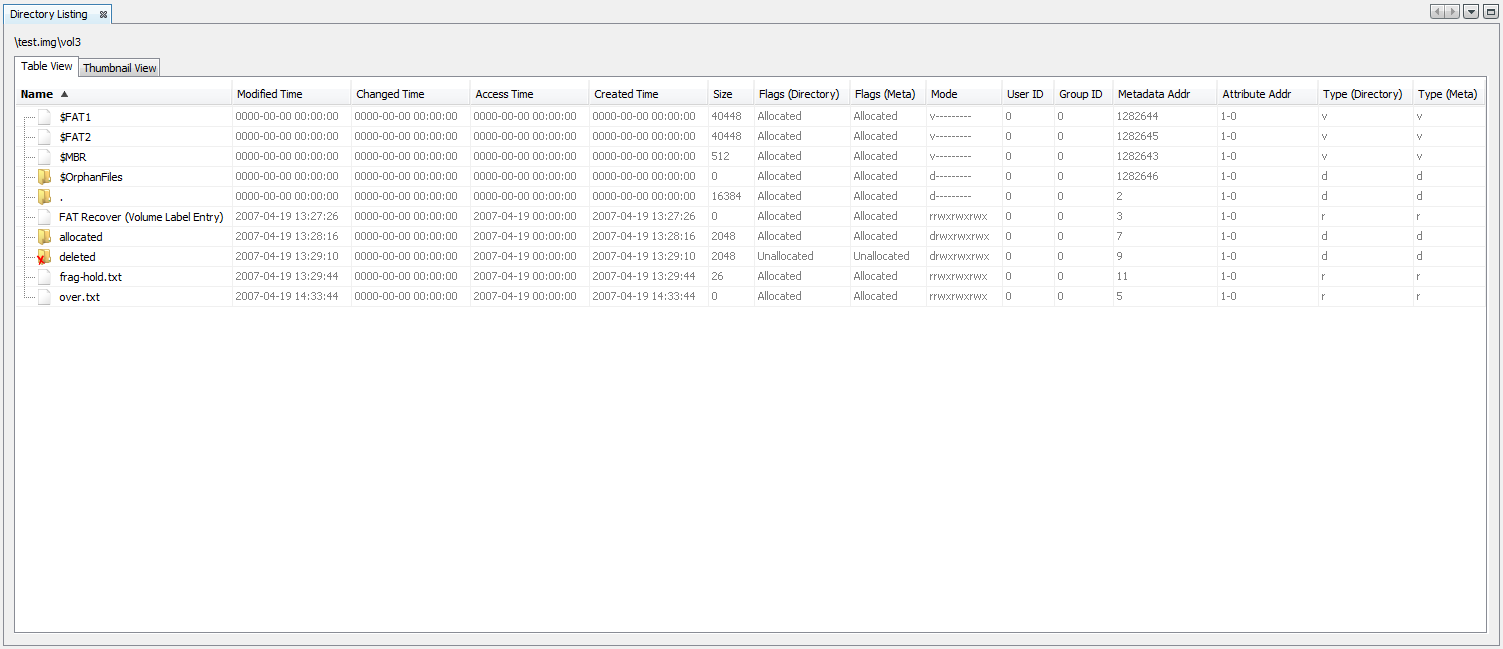
Result Content Viewer
Result Content Viewer shows the artifacts (saved results) associated with the item selected in the Result Viewer. Example Below is an example of "Result Content Viewer" window:
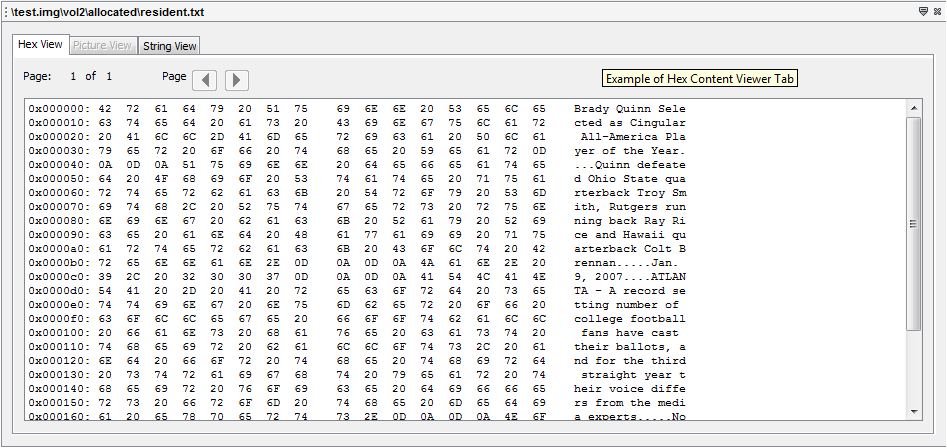
Hex Content Viewer
Hex Content Viewer shows you the raw and exact contents of a file. In this Hex Content Viewer, the data of the file is represented as hexadecimal values grouped in 2 groups of 8 bytes, followed by one group of 16 ASCII characters which are derived from each pair of hex values (each byte). Non-printable ASCII characters and characters that would take more than one character space are typically represented by a dot (".") in the following ASCII field.
Example
Below is an example of "Hex Content Viewer" window:
Media Content Viewer
The Media Content Viewer will show a picture or video file. Video files can be played and paused. The size of the picture or video will be reduced to fit into the screen. If you want more complex analysis of the media, then you must export the file.
If you select an non-picture file or an unsupported picture format on the "Result Viewers", this tab will be disabled.
Example
Here's one of the example of the "Media Content Viewer":

String Content Viewer
Strings Content Viewer scans (potentially binary) data of the file / folder and searches it for data that could be text. When appropriate data is found, the String Content Viewer shows data strings extracted from binary, decoded, and interpreted as UTF8/16 for the selected script/language.
Note that this is different from the Text Content Viewer, which displays the text for a file that is stored in the keyword search index. The results may be the same or they could be different, depending how the data were interpreted by the indexer.
Example
Below is an example of "String Content Viewer" window:
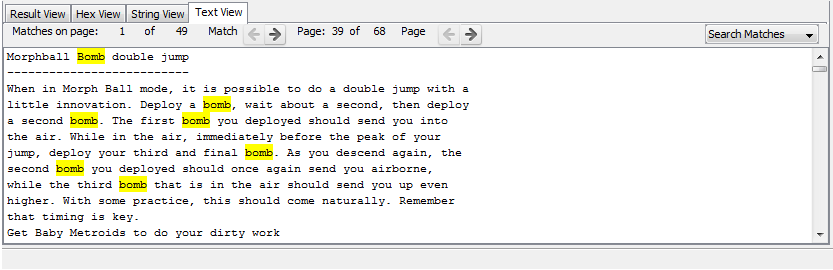
Text Content Viewer
Text Content Viewer uses the keyword search index that may have been populated during Image Ingest. If a file has text stored in the index, then this tab will be enabled and it will be displayed to the user if a file or a result associated with a file is selected.
This tab may have more text on it than the "String View", which relies on searching the file for text-looking data. Some files, like PDF, will not have text-looking data at the byte-level, but the keyword indexing process knows how to interpret a PDF file and produce text. For the files the indexer knows about, there may be the METADATA section at the end of the displayed extracted text. If an indexed document contains any metadata (such as creation date, author, etc), it will be displayed there. Note that, unlike the "String View", the Text View does not have its built-in settings for the script/language to use for extracted strings. This is because the script/language is used at indexing time, and that setting is associated with the Keyword Search indexer, not the viewer.
If this tab is not enabled, then either the file has no text or you did not enable Keyword Search as an ingest module. Note that this viewer is also used to display highlighted keyword hits when operated in the "Search Matches" mode, selected on the right-hand side of the viewer's toolbar.