|
Sleuth Kit Java Bindings (JNI)
4.13.0
Java bindings for using The Sleuth Kit
|
|
Sleuth Kit Java Bindings (JNI)
4.13.0
Java bindings for using The Sleuth Kit
|
The blackboard allows modules (in Autopsy or other frameworks) to communicate and store results. A module can post data to the blackboard so that subsequent modules can see its results. It can also query the blackboard to see what previous modules have posted.
The blackboard is a collection of artifacts. Each artifact is a either a data artifact or an analysis result. In general, data artifacts record data found in the image (ex: a call log entry) while analysis results are more subjective (ex: a file matching a user-created interesting file set rule). Each artifact has a type, such as web browser history, EXIF, or GPS route. The Sleuth Kit has many artifact types already defined (see org.sleuthkit.datamodel.BlackboardArtifact.ARTIFACT_TYPE and the artifact catalog) and you can also create your own.
Each artifact has a set of name-value pairs called attributes. Attributes also have types, such as URL, created date, or device make. The Sleuth Kit has many attribute types already defined (see org.sleuthkit.datamodel.BlackboardAttribute.ATTRIBUTE_TYPE) and you can also create your own.
See the artifact catalog for a list of artifacts and the attributes that should be associated with each.
There are two special types of artifacts that are used a bit differently than the rest.
The first is the org.sleuthkit.datamodel.BlackboardArtifact.ARTIFACT_TYPE.TSK_GEN_INFO artifact. A Content object should have only one artifact of this type and it is used to store a independent attributes that will not be displayed in the UI. Autopsy used to store the MD5 hash and MIME type in TSK_GEN_INFO, but they are now in the files table of the database. There are special methods to access this artifact to ensure that only a single TSK_GEN_INFO artifact is created per Content object and that you get a cached version of the artifact. These methods will be given in the relevant sections below.
The second special type of artifact is the TSK_ASSOCIATED_OBJECT. All artifacts are created as the child of a file or artifact. This TSK_ASSOCIATED_OBJECT is used to make additional relationships with files and artifacts apart from this parent-child relationship. See the Associated Objects section below.
Modules can access the blackboard from either org.sleuthkit.datamodel.SleuthkitCase, org.sleuthkit.datamodel.Blackboard, or a org.sleuthkit.datamodel.Content object. The methods associated with org.sleuthkit.datamodel.Content all limit the Blackboard to a specific file.
First you need to decide what type of artifact you are making and what category it is. Artifact types fall into two categories:
Consult the artifact catalog for a list of built-in types and what categories they belong to. If you are creating a data artifact, you can optionally add an OS account to it. If you are creating an analysis result, you can optionally add a score and other notes about the result. Note that you must use the category defined in the artifact catalog for each type or you will get an error. For example, you can't create a web bookmark analysis result.
There are may ways to create artifacts, but we will focus on creating them through the Blackboard class or directly through a Content object. Regardless of how they are created, all artifacts must be associated with a Content object.
Attributes are created by making a new instance of org.sleuthkit.datamodel.BlackboardAttribute using one of the various constructors. Attributes can either be added when creating the artifact using the methods in the above list or at a later time using org.sleuthkit.datamodel.BlackboardArtifact.addAttribute() (or org.sleuthkit.datamodel.BlackboardArtifact.addAttributes() if you have several to add - it’s faster). Note that you should not manually add attributes of type JSON for standard attribute types such as TSK_ATTACHMENTS or TSK_GEO_TRACKPOINTS. Instead, you should use the helper classes in org.sleuthkit.datamodel.blackboardutils.attributes or org.sleuthkit.datamodel.blackboardutils to create your artifacts.
If you want to create an attribute in the TSK_GEN_INFO artifact, use org.sleuthkit.datamodel.Content.getGenInfoArtifact() to ensure that you do not create a second TSK_GEN_INFO artifact for the file and to ensure that you used the cached version (which will be faster for you).
In some cases, it may not be clear if you should post multiple single-attribute artifacts for a file or post a single multiple-attribute artifact. Here are some guidelines:
Artifact helpers are a set of classes that make it easier for module developers to create artifacts. These classes provide methods that abstract the details of artifacts and attributes, and provide simpler and more readable API.
The following helpers are available:
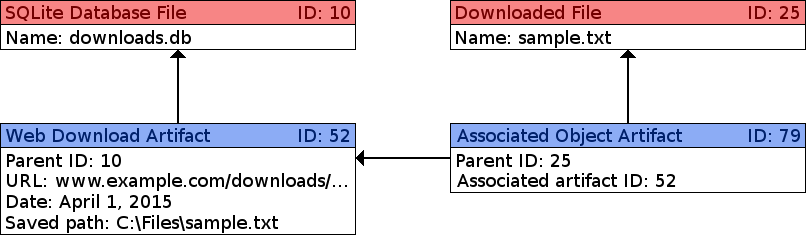
Artifacts should be created as children of the file that they were derived or parsed from. For example, a TSK_WEB_DOWNLOAD artifact would be a child of the browser's SQLite database that was parsed. This creates a relationship between the source file and the artifact. But, sometimes you also want to make a relationship between the artifact and another file (or artifact). This is where the TSK_ASSOCIATED_OBJECT artifact comes in.
For example, suppose you have a module that parses a SQLite database that has a log of downloaded files. Each entry might contain the URL the file was downloaded from, timestamp information, and the location the file was saved to on disk. This data would be saved in a TSK_WEB_DOWNLOAD artifact that would be a child of the SQLite database. But suppose the downloaded file also exists in our image. It would be helpful to link that file to our TSK_WEB_DOWNLOAD artifact to show when and where it was downloaded from.
We achieve this relationship by creating a TSK_ASSOCIATED_OBJECT artifact on the downloaded file. This artifact stores the ID of the TSK_WEB_DOWNLOAD artifact in a TSK_ASSOCIATED_ARTIFACT attribute so we have a direct link from the file to the artifact that shows where it came from.
You can find artifacts by querying the blackboard in a variety of ways. It is preferable to use the methods that specifically return either data artifacts or analysis results since these will contain the complete information for the artifact. You can use the more general "Artifact" or "BlackboardArtifact" methods to get both, however these results will only contain the blackboard attributes and not any associated OS account or score/justification.
You can find artifacts using a variety of ways:
This section outlines how to create artifact and attribute types because the standard ones do not meet your needs. These custom artifacts will be displayed in the Autopsy UI alongside the built in artifacts and will also appear in the reports.
org.sleuthkit.datamodel.SleuthkitCase.addBlackboardArtifactType() is used to create a custom artifact. Give it the display name, unique name and category (data artifact or analysis result) and it will return a org.sleuthkit.datamodel.BlackboardArtifact.Type object with a unique ID. You will need to call this once for each case to create the artifact ID. You can then use this ID to make an artifact of the given type. To check if the artifact type has already been added to the blackboard or to get the ID after it was created, use org.sleuthkit.datamodel.SleuthkitCase.getArtifactType().
To create custom attributes, use org.sleuthkit.datamodel.SleuthkitCase.addArtifactAttributeType() to create the artifact type and get its ID. Like artifacts, you must create the attribute type for each new case. To get a type after it has been created in the case, use org.sleuthkit.datamodel.SleuthkitCase.getAttributeType(). Your attribute will be a name-value pair where the value is of the type you specified when creating it. The current types are: String, Integer, Long, Double, Byte, Datetime, and JSON. If you believe you need to create an attribute with type JSON, please read the overview and tutorial sections below.
Note that "TSK" is an abbreviation of "The Sleuth Kit." Artifact and attribute type names with a "TSK_" prefix indicate the names of standard or "built in" types. User-defined artifact and attribute types should not be given names with "TSK_" prefixes.
This section will give a quick overview of how to use JSON attributes. If this is your first time using JSON attributes please read the JSON Attribute Tutorial below as well.
Attributes with values of type JSON should be used only when the data can't be stored as an unordered set of attributes. To date, the most common need for this has been where an artifact needs to store multiple ordered instances of the same type of data in a single artifact. For example, one of the standard JSON attributes is TSK_GEO_TRACKPOINTS which stores an ordered list of track points, each containing coordinates, a timestamp, and other data.
The underlying data in a JSON attribute will be either an array of individual attributes or an array of maps of attributes. For example, an artifact containing two track points could look similar to this (some attributes have been removed for brevity):
{"pointList":
[
{"TSK_DATETIME":1255822646,
"TSK_GEO_LATITUDE":47.644548,
"TSK_GEO_LONGITUDE":-122.326897},
{"TSK_DATETIME":1255822651,
"TSK_GEO_LATITUDE":47.644548,
"TSK_GEO_LONGITUDE":-122.326897}
]
}
In practice you will not be required to deal with the raw JSON, but it is important to note that in the name/value pairs, the name should always be the name of a blackboard artifact type. This allows Autopsy to better process each attribute, for example by displaying timestamps in human-readable format.
To start, follow the instructions in the Making Custom Artifacts and Attributes section above to create your custom attribute with value type JSON. Next you'll need to put your data into the new attribute. There are two general methods:
Assuming you go the POJO route (highly recommended), there are two options for creating your class. As discussed above, each field name should match an attribute name (either built-in or custom). You could create a class like this:
class WebLogEntry {
long TSK_DATETIME;
String TSK_URL;
The downside here is that your code will likely be a bit less readable like this. The other option is to use annotations specifying which attribute type goes with each of your fields, like this:
class WebLogEntry {
@SerializedName("TSK_DATETIME")
long accessDate;
@SerializedName("TSK_URL")
String urlVisited;
You may need to make multiple POJOs to hold the data you need to serialize. This would most commonly happen if you want to store a list of values. In our example above, we would likely need to create a WebLog class to hold our list of WebLogEntry objects.
Now we need to convert our object into a JSON attribute. The easiest way to do this using the method org.sleuthkit.datamodel.blackboardutils.attributes.BlackboardJsonAttrUtil.toAttribute(). This method will return a BlackboardAttribute serialized from your object. You can then add this new attribute to your BlackboardArtifact.
If you need to process JSON attributes you created and you created your own POJO as discussed in the previous section, you can use the method org.sleuthkit.datamodel.blackboardutils.attributes.BlackboardJsonAttrUtil.fromAttribute(). It will return an instance of your class containing the data from a given BlackboardAttribute.
The following describes an example of when you might need a JSON-valued attribute and the different methods for creating one. It also shows generally how to create custom artifacts and attributes so may be useful even if you do not need a JSON-type attribute.
Suppose we had a module that could record the last few times an app was accessed and which user opened it. The data we'd like to store for one app could have the form:
App name: Sample App
Logins: user1, 2020-03-31 10:06:37 EDT
user2, 2020-03-30 06:19:57 EDT
user1, 2020-03-26 18:59:57 EDT
We could make a separate artifact for each of those logins (each with the app name, user name, and timestamp) it might be nicer to have them all under one and keep them in order. This is where the JSON-type attribute comes into play. We can store all the login data in a single blackboard attribute.
To start, we'll need to create our new artifact and attribute types. We'll need a new artifact type to hold our login data and a new attribute type to hold the logins themselves (this will be our JSON attribute). We'll use a standard attribute later for the app name. This part should only be done once, possibly in the startUp() method of your ingest module.
SleuthkitCase skCase = Case.getCurrentCaseThrows().getSleuthkitCase();
// Add the new artifact type to the case if it does not already exist
String artifactName = "APP_LOG";
String artifactDisplayName = "Application Logins";
BlackboardArtifact.Type artifactType = skCase.getArtifactType(artifactName);
if (artifactType == null) {
artifactType = skCase.addBlackboardArtifactType(artifactName, artifactDisplayName);
}
// Add the new attribute type to the case if it does not already exist
String attributeName = "LOGIN_DATA";
String attributeDisplayName = "Login Data";
BlackboardAttribute.Type loginDataAttributeType = skCase.getAttributeType(attributeName);
if (loginDataAttributeType == null) {
loginDataAttributeType = skCase.addArtifactAttributeType(attributeName,
BlackboardAttribute.TSK_BLACKBOARD_ATTRIBUTE_VALUE_TYPE.JSON, attributeDisplayName);
}
You'll want to save the new artifact and attribute type objects to use later.
Now our ingest module can create artifacts for the data it extracts. In the code below, we create our new "APP_LOG" artifact, add a standard attribute for the user name, and then create and store a JSON-formatted string which will contain each entry from the "loginData" list. Note that manually creating the JSON as shown below is not recommeded and is just for illustrative purposes - an easier method will be given afterward.
BlackboardArtifact art = content.newArtifact(artifactType.getTypeID());
List<BlackboardAttribute> attributes = new ArrayList<>();
attributes.add(new BlackboardAttribute(BlackboardAttribute.ATTRIBUTE_TYPE.TSK_PROG_NAME, moduleName, appName));
String jsonLoginStr = "{ LoginData : [ ";
String dataStr = "";
for(LoginData data : loginData) {
if (!dataStr.isEmpty()) {
dataStr += ", ";
}
dataStr += "{\"TSK_USER_NAME\" : \"" + data.getUserName() + "\", "
+ "\"TSK_DATATIME\" : \"" + data.getTimestamp() + "\"} ";
}
jsonLoginStr += dataStr + " ] }";
attributes.add(new BlackboardAttribute(loginDataAttributeType, moduleName, jsonLoginStr));
art.addAttributes(attributes);
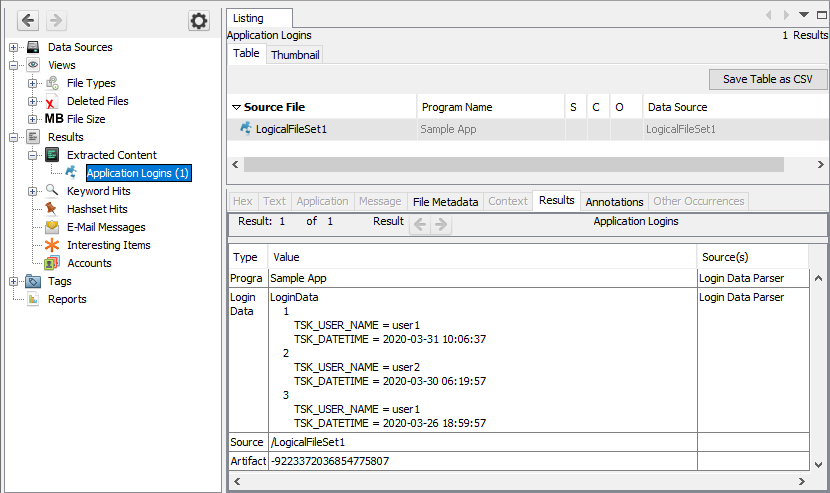
It is important that each of the name-value pairs starts with an existing blackboard attribute name. This will allow Autopsy to use the corresponding value, for example, to extract out a timestamp to show this artifact in the Timeline viewer. Here's what our newly-created artifact will look like in Autopsy:
The above method for storing the data works but formatting the JSON attribute manually is prone to errors. Luckily, in most cases instead of writing the JSON ourselves we can serialize a Java object. If the data that will go into the JSON attribute is contained in plain old Java objects (POJOs), then we can add annotations to that class to produce the JSON automatically. Here they've been added to the LoginData class:
// Requires package com.google.gson.annotations.SerializedName;
private class LoginData {
@SerializedName("TSK_USER_NAME")
String userName;
@SerializedName("TSK_DATETIME")
long timestamp;
LoginData(String userName, long timestamp) {
this.userName = userName;
this.timestamp = timestamp;
}
}
We want our JSON attribute to store a list of these LoginData objects, so we'll create another POJO for that:
private class LoginDataLog {
List<LoginData> dataLog;
LoginDataLog() {
dataLog = new ArrayList<>();
}
void addData(LoginData data) {
dataLog.add(data);
}
}
Now we use org.sleuthkit.datamodel.blackboardutils.attributes.BlackboardJsonAttrUtil.toAttribute() to convert our LoginDataLog object into a BlackboardAttribute, greatly simplifying the code. Here, "dataLog" is an instance of a LoginDataLog object that contains all of the login data.
BlackboardArtifact art = content.newArtifact(artifactType.getTypeID()); List<BlackboardAttribute> attributes = new ArrayList<>(); attributes.add(new BlackboardAttribute(BlackboardAttribute.ATTRIBUTE_TYPE.TSK_PROG_NAME, moduleName, appName)); attributes.add(BlackboardJsonAttrUtil.toAttribute(loginDataAttributeType, moduleName, dataLog)); art.addAttributes(attributes);
Copyright © 2011-2024 Brian Carrier. (carrier -at- sleuthkit -dot- org)
This work is licensed under a
Creative Commons Attribution-Share Alike 3.0 United States License.

