What Does It Do
The Hash Database Lookup Module calculates MD5 hash values for files and looks up hash values in a database to determine if the file is notable, known (in general), or unknown.
Configuration
The Hash Database Management window is where you can set and update your hash database information. Hash databases are used to identify files that are 'known'.
- Known good files are those that can be safely ignored. This set of files frequently includes standard OS and application files. Ignoring such uninteresting-to-the-investigator files, can greatly reduce image analysis time.
- Notable (or known bad) files are those that should raise awareness. This set will vary depending on the type of investigation, but common examples include contraband images and malware.
Importing Hashsets
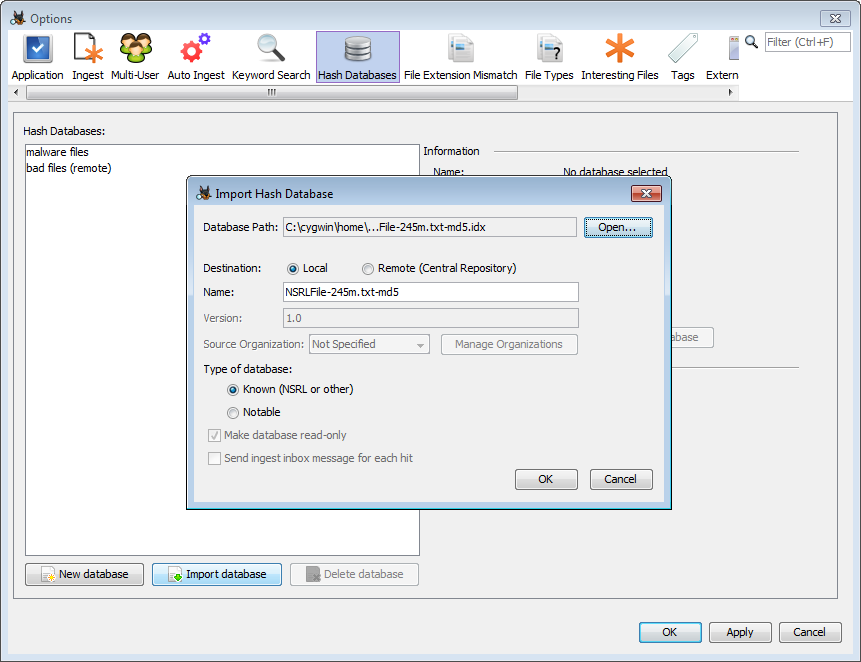
To import an existing hashset, use the "Import Database" button on the Hash Databases options panel. This will bring up a dialog to import the file.
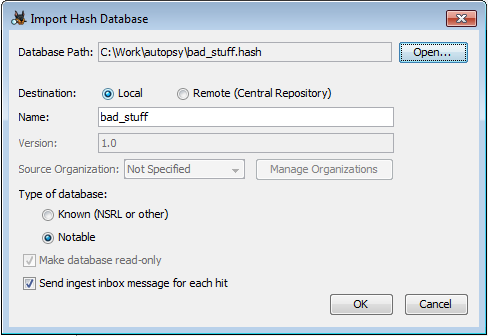
Database Path - The path to the hashset you are importing. Autopsy supports the following formats:
- Text: One hash starting each line. For example, the output from running the md5, md5sum, or md5deep program on a set of files (*.txt)
- Index only: Generated by Sleuth Kit/Autopsy. The NSRL is available in this format for use with Autopsy (see below) (*.idx)
- Sleuth Kit/Autopsy format database: SQLite hashsets created by Autopsy (*.kdb)
- EnCase: An EnCase hashset file (*.hash)
- HashKeeper: Hashset file conforming to the HashKeeper standard (*.hsh)
Destination - The Destination field refers to where the hashset will be stored.
- Local: The hashset file will be used from original the location on disk
- Remote: The hashset will be copied into the central repository. When using a PostgreSQL central repository, this allows multiple users to easily share the same hashsets.
Name - Display name of the hashset. One will be suggested based on the file name, but this can be changed.
Version - The version of the hashset can only be entered when importing the hashset into the central repository. Additionally, no version can be entered if the database is not read-only.
Source Organization - The organization can only be entered when importing the hashset into the central repository. See the section on managing organizations for more information.
Type of database - All entries in the hashset should either be "known" (can be safely ignored) or "notable" (could be indicators of suspicious behavior).
Make database read-only - The read-only setting is only active when importing the hashset into the central repository. A read-only database can not have new hashes added to it through either the Hash Database options panel or the context menu. For locally imported hashsets, whether they can be written to is dependent on the type of hashset. Autopsy format databases (*.kdb) can be edited, but all other types will be read-only.
Send ingest inbox message for each hit - Determines whether a message is sent for each matching file. This can not be enabled for a "known" database.
Indexing
After importing the hashset, you may have to index it before it can be used. For most hashset types, Autopsy needs an index of the hashset to actually use a hash database. It can create the index if you import only the hashset. Any hashsets that require an index will be displayed in red, and their "Index Status" will indicate that an index needs to be created. This is done simply by using the Index button.
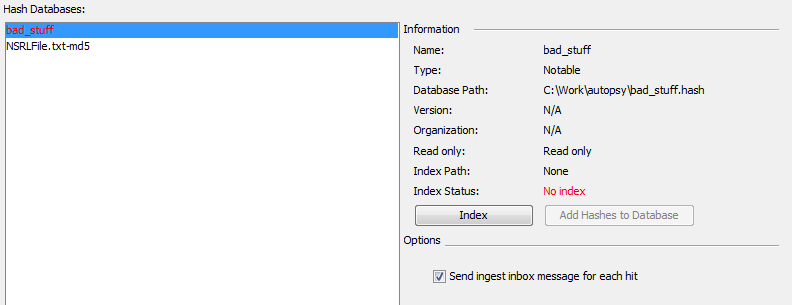
Autopsy uses the hash database management system from The Sleuth Kit. You can manually create an index using the 'hfind' command line tool or you can use Autopsy. If you attempt proceed without indexing a database, Autopsy will offer to automatically produce an index for you. You can also specify only the index file and not use the full hashset - the index file is sufficient to identify known files. This can save space. To do this, specify the .idx file from the Hash Database Management window.
Creating Hashsets
New hashsets can be created using the "New Database" button. The fields are mostly the same as the import dialog described above.
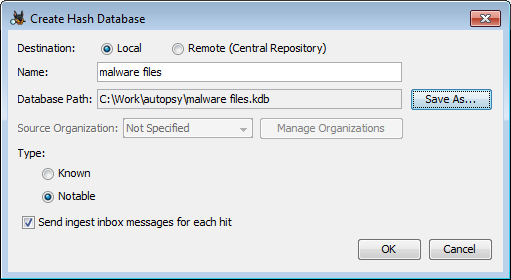
In this case, the Database Path is where the new database will be stored. If the central repository is being used then this field is not needed.
Using Hashsets
There is an ingest module that will hash the files and look them up in the hashsets. It will flag files that were in the notable hashset and those results will be shown in the Results tree of the Tree Viewer. Other ingest modules are able to use the known status of a file to decide if they should ignore the file or process it. You can also see the results in the File Search window. There is an option to choose the 'known status'. From here, you can do a search to see all 'notable' files. From here, you can also choose to ignore all 'known' files that were found in the NSRL. You can also see the status of the file in a column when the file is listed.
NIST NSRL
Autopsy can use the NIST NSRL to detect 'known files'. The NSRL contains hashes of 'known files' that may be good or bad depending on your perspective and investigation type. For example, the existence of a piece of financial software may be interesting to your investigation and that software could be in the NSRL. Therefore, Autopsy treats files that are found in the NSRL as simply 'known' and does not specify good or bad. Ingest modules have the option of ignoring files that were found in the NSRL.
To use the NSRL, you may download a pre-made index from http://sourceforge.net/projects/autopsy/files/NSRL. Download the NSRL-XYZm-autopsy.zip (where 'XYZ' is the version number. As of this writing, it is 247) and unzip the file. Use the "Tools", "Options" menu and select the "Hash Database" tab. Click "Import Database" and browse to the location of the unzipped NSRL file. You can change the Hash Set Name if desired. Select the type of database desired, choosing "Send ingest inbox message for each hit" if desired, and then click "OK".
Using the Module
Ingest Settings
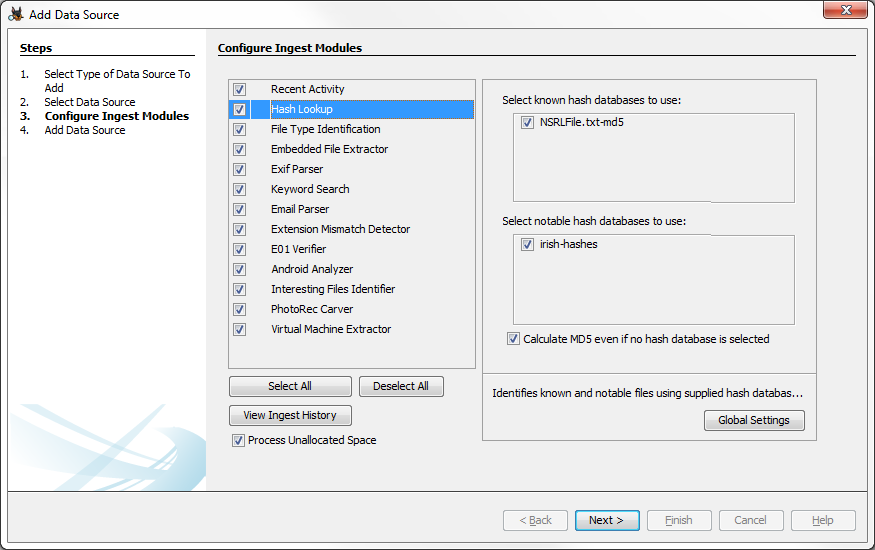
When hashsets are configured, the user can select the hashsets to use during the ingest process.
Seeing Results
Results show up in the tree as "Hashset Hits", grouped by the name of the hash set.