What Does It Do
The Keyword Search module facilitates both the ingest portion of searching and also supports manual text searching after ingest has completed (see Ad Hoc Keyword Search). It extracts text from files being ingested, selected reports generated by other modules, and results generated by other modules. This extracted text is then added to a Solr index that can then be searched.
Autopsy tries its best to extract the maximum amount of text from the files being indexed. First, the indexing will try to extract text from supported file formats, such as pure text file format, MS Office Documents, PDF files, Email, and many others. If the file is not supported by the standard text extractor, Autopsy will fall back to a string extraction algorithm. String extraction on unknown file formats or arbitrary binary files can often extract a sizeable amount of text from a file, often enough to provide additional clues to reviewers. String extraction will not extract text strings from encrypted files.
Autopsy ships with some built-in lists that define regular expressions and enable the user to search for Phone Numbers, IP addresses, URLs and E-mail addresses. However, enabling some of these very general lists can produce a very large number of hits, and many of them can be false-positives. Regular expressions can potentially take a long time to complete.
Once files are placed in the Solr index, they can be searched quickly for specific keywords, regular expressions, or keyword search lists that can contain a mixture of keywords and regular expressions. Search queries can be executed automatically during the ingest run or at the end of the ingest, depending on the current settings and the time it takes to ingest the image.
Keyword Search Configuration Dialog
The keyword search configuration dialog has three tabs, each with its own purpose:
- The Lists tab is used to add, remove, and modify keyword search lists.
- The String Extraction tab is used to enable language scripts and extraction type.
- The General Settings tab is used to configure the ingest timings and display information.
Lists tab
The Lists tab is used to create/import and add content to keyword lists. To create a list, select the 'New List' button and choose a name for the new Keyword List. Once the list has been created, keywords can be added to it (see Creating Keywords for more information on keyword types). Lists can be added to the keyword search ingest process; searches will happen at regular intervals as content is added to the index.
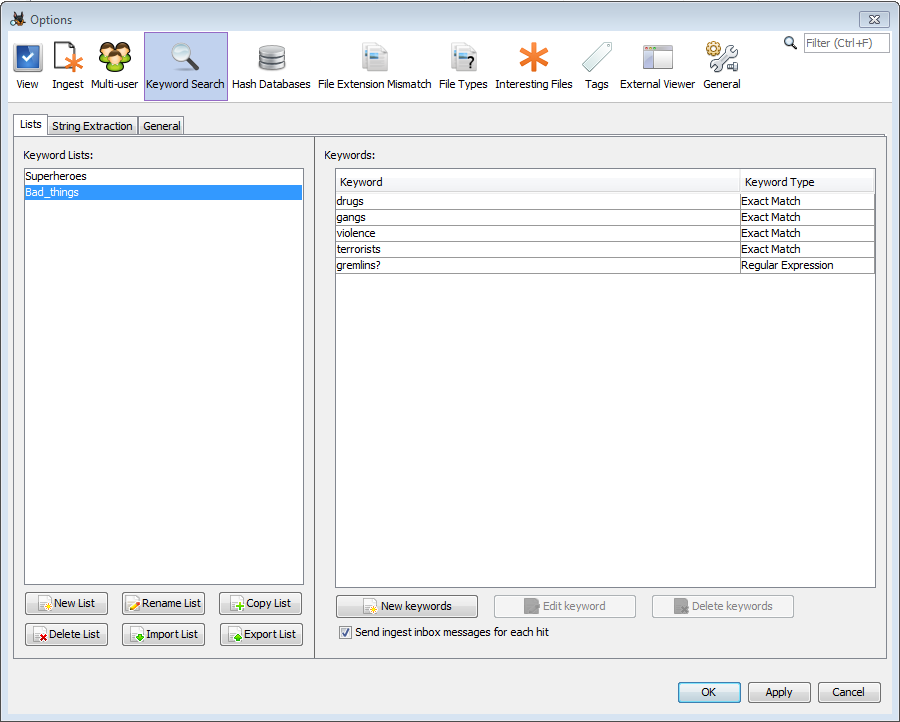
The lists of keywords can be found on the left side of the panel. New lists can be created, existing lists can be renamed, copied, exported, or deleted, and lists can be imported. Autopsy supports importing Encase tab-delimited lists as well as lists created previously with Autopsy. For Encase lists, folder structure and hierarchy is ignored. There is currently no way to export lists for use with Encase, but lists can be exported to share between Autopsy users.
Once a keyword list is selected all keywords in that list will be displayed on the right side of the tab. The "New Keywords" button can be used to add one or more entries to the list, and the "Edit keyword" and "Delete keywords" buttons can alter the existing entries.

New entries can be typed into the dialog or pasted from the clipboard. All entries added at once must be the same type of match (exact, substring, or regex), but the dialog can be used multiple times to add keywords to the keyword list. Refer to the Creating Keywords section for an explanation of each keyword type.
Under the Keyword list is the option to send ingest inbox messages for each hit. If this is enabled, each keyword hit for that list will be accessible through the yellow triangle next to the Keyword Lists button. This feature gives you a quick way to view your most important keyword search results.

String Extraction tab
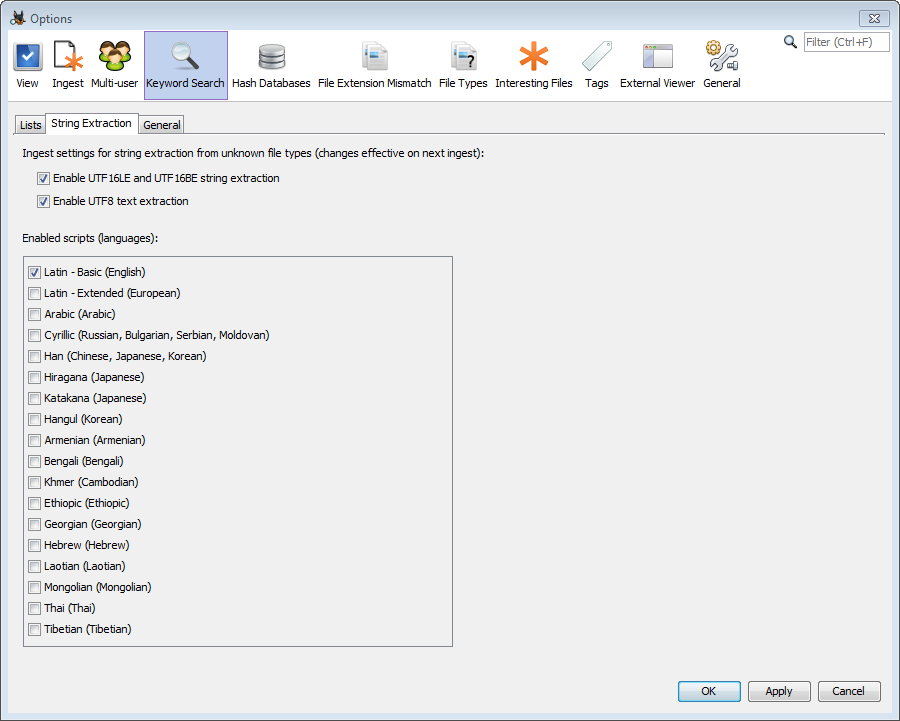
The string extraction setting defines how strings are extracted from files from which text cannot be extracted because their file formats are not supported. This is the case with arbitrary binary files (such as the page file) and chunks of unallocated space that represent deleted files. When we extract strings from binary files we need to interpret sequences of bytes as text differently, depending on the possible text encoding and script/language used. In many cases we don't know in advance what the specific encoding/language the text is encoded in. However, it helps if the investigator is looking for a specific language, because by selecting less languages the indexing performance will be improved and the number of false positives will be reduced.
The default setting is to search for English strings only, encoded as either UTF8 or UTF16. This setting has the best performance (shortest ingest time). The user can also use the String Viewer first and try different script/language settings, and see which settings give satisfactory results for the type of text relevant to the investigation. Then the same setting that works for the investigation can be applied to the keyword search ingest.
General Settings tab

NIST NSRL Support
The hash lookup ingest service can be configured to use the NIST NSRL hash set of known files. The keyword search advanced configuration dialog "General" tab contains an option to skip keyword indexing and search on files that have previously marked as "known" and uninteresting files. Selecting this option can greatly reduce size of the index and improve ingest performance. In most cases, user does not need to keyword search for "known" files.
Result update frequency during ingest
To control how frequently searches are executed during ingest, the user can adjust the timing setting available in the keyword search advanced configuration dialog "General" tab. Setting the number of minutes lower will result in more frequent index updates and searches being executed and the user will be able to see results more in real-time. However, more frequent updates can affect the overall performance, especially on lower-end systems, and can potentially lengthen the overall time needed for the ingest to complete.
One can also choose to have no periodic searches. This will speed up the ingest. Users choosing this option can run their keyword searches once the entire keyword search index is complete.
Using the Module
Search queries can be executed manually by the user at any time, as long as there are some files already indexed and ready to be searched. Searching before indexing is complete will naturally only search indexes that are already compiled.
See Ingest for more information on ingest in general.
Once there are files in the index, Ad Hoc Keyword Search will be available for use to manually search at any time.
Ingest Settings
The Ingest Settings for the Keyword Search module allow the user to enable or disable the specific built-in search expressions, Phone Numbers, IP Addresses, Email Addresses, and URLs. Using the Advanced button (covered below), one can add custom keyword groups.

Seeing Results
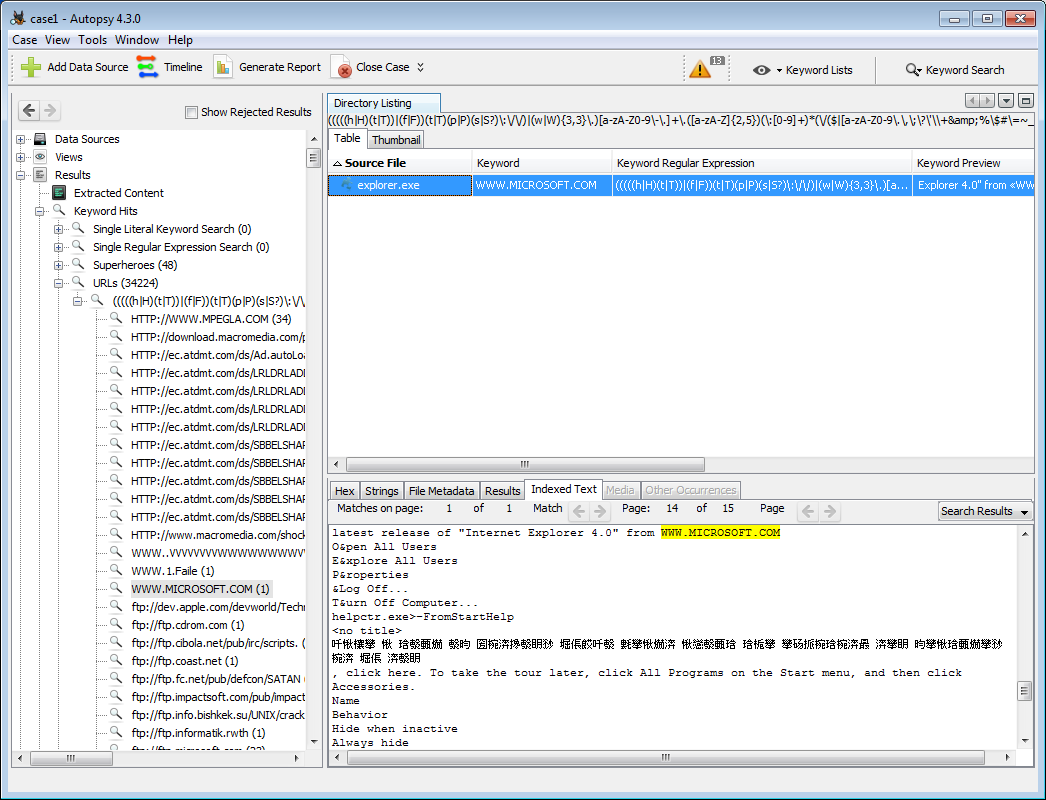
The Keyword Search module will save the search results regardless whether the search is performed by the ingest process, or manually by the user. The saved results are available in the Directory Tree in the left hand side panel.
The keyword results will appear in the tree under "Keyword Hits". Each keyword search term will display the number of matches, and can be expanded to show the matches. From here, clicking on one of the matches will show a list of files on the right side of the screen. Select a file and go to the Indexed Text tab to see exactly where the matches occurred in the file.