Table des matières
Aperçu
Autopsy utilise Apache Solr pour stocker des index de texte de mots clés. Un serveur central est nécessaire dans un cluster multi-utilisateurs pour maintenir et rechercher ces index.
Un nouvel index de texte est créé pour chaque cas. L'index peut être stocké soit sur un stockage partagé, soit sur le lecteur local du ou des serveurs Solr (une grande quantité de stockage local est requise).
ZooKeeper intégré à Solr est également utilisé comme service de coordination pour Autopsy.
Si vous avez déjà installé Solr 4 avec une version précédente d'Autopsy, veuillez consulter la page Mise à niveau vers Autopsy 4.18.0 (avec Solr 8) pour plus d'informations sur la manière d'ouvrir les anciens cas après la mise à niveau et de migrer les données.
REMARQUE : ce document suppose que vous exécuterez Solr sur Windows en tant que service. Vous pouvez ne pas l'exécuter en tant que service ou l'exécuter sur une autre plate-forme, mais vous devrez comprendre les étapes de ce document pour y parvenir.
Conditions préalables
Vous aurez besoin de:
- Une version 64 bits de Java 8 Runtime Environment (JRE) que vous pourrez trouver sur https://github.com/ojdkbuild/ojdkbuild. (Lien de téléchargement)
- Une version Autopsy pré-packagée avec Solr que vous pourrez trouver ici. Cela contient Solr, NSSM pour le faire fonctionner en tant que service, ainsi que les fichiers de configuration de schéma nécessaires.
- Une machine accessible en réseau sur laquelle installer Solr. Notez que le processus Solr peut avoir besoin d'écrire sur un lecteur de stockage partagé (si c'est ainsi que vous le configurez) et aura donc besoin des autorisations adéquates.
Installation de Solr
Installation du JRE
Solr nécessite un environnement d'exécution Java (JRE), qui peut déjà être installé. Vous pouvez tester cela en exécutant "where java" à partir de la ligne de commande. Si vous voyez une sortie similaire aux résultats ci-dessous, vous avez un JRE.

Si vous avez besoin du JRE, utilisez le lien figurant dans la section Conditions préalables ci-dessus pour télécharger le programme d'installation. Acceptez les paramètres par défaut lors de l'installation.
Configuration de Solr
Suivez ces étapes pour configurer Solr:
-
Extrayez l'archive solr-8.6.3.zip de l'emplacement indiqué dans la section Conditions préalables dans un répertoire de votre choix. Le reste de ce document suppose que l'archive est extraite dans le répertoire
"C:\solr-8.6.3". -
Aller dans le répertoire
"C:\solr-8.6.3\bin"et ouvrez le fichier"solr.in.cmd"dans un éditeur de texte.
-
Recherchez chaque "TODO" et spécifiez un chemin valide pour chacun des paramètres de configuration requis. Ces paramètres seront décrits en détail ci-dessous.

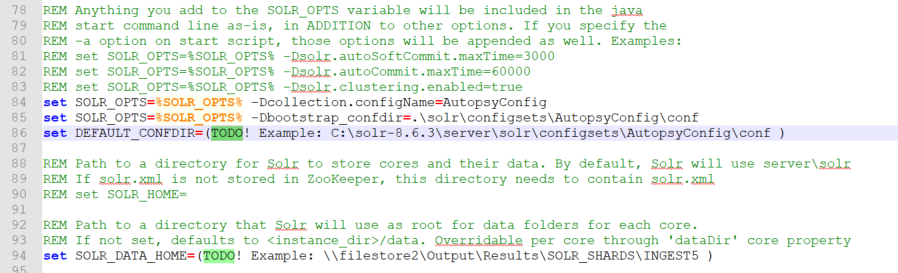
Paramètres de configuration Solr
Paramètres de configuration requis pour Solr:
-
JAVA_HOME – chemin d'accès à l'installation du JRE 64 bits. Par exemple
"JAVA_HOME=C:\Program Files\Java\jre1.8.0_151"ou"JAVA_HOME=C:\Program Files\ojdkbuild\java-1.8.0-openjdk-1.8.0.222-1" -
DEFAULT_CONFDIR – chemin vers le répertoire de configuration d'Autopsy. Si l'archive Solr a été extraite dans le répertoire
"C:\solr-8.6.3", alors ce chemin sera"C:\ solr-8.6.3\server\solr\configsets\AutopsyConfig\conf". N'incluez pas de guillemets autour du chemin. - SOLR_JAVA_MEM - La taille du tas JVM Solr doit être aussi grande que les ressources de la machine Solr le permettent, au moins la moitié de la RAM totale disponible sur la machine. Une règle empirique serait d'utiliser "set SOLR_JAVA_MEM=-Xms2G -Xmx40G" pour une machine avec 64 Go de RAM, "set SOLR_JAVA_MEM=-Xms2G -Xmx20G" pour une machine avec 32 Go de RAM, et "set SOLR_JAVA_MEM=-Xms2G -Xmx8G" pour une machine avec 16 Go de RAM. Veuillez consulter la rubrique dépannage pour plus d'informations sur l'utilisation du tas Solr et sur les informations de dépannage.
-
SOLR_DATA_HOME – emplacement où les index Solr seront stockés. Si ce n'est pas configuré, les index seront stockés dans le répertoire
"C:\solr-8.6.3\server\solr". REMARQUE: pour les cas d'Autopsy composés d'un grand nombre de sources de données, les index Solr peuvent devenir très volumineux (des centaines de Go ou de To), ils devront donc probablement être stockés sur un partage réseau plus important.
Paramètres de configuration Solr facultatifs:
- SOLR_HOST – par défaut, le nom du nœud Solr est "localhost". Si plusieurs nœuds Solr doivent être utilisés dans le cadre d'un SolrCloud, spécifiez le nom d'hôte de l'ordinateur actuel dans la variable SOLR_HOST.
Emplacement du fichier d'index de texte Solr
Note importante: les versions précédentes d'Autopsy (Autopsy 4.17.0 et versions antérieures) stockaient les index de texte Solr dans le répertoire de sortie de cas. En conséquence, les index Solr étaient supprimés si un utilisateur supprimait le répertoire de sortie de cas. Solr 8 (c'est-à-dire pour Autopsy 4.18.0 et versions ultérieures) ne stocke plus les fichiers d'index de texte Solr dans le répertoire de sortie du cas, mais les stocke à la place dans un emplacement défini par le paramètre SOLR_DATA_HOME. Par conséquent, si un utilisateur choisit de supprimer manuellement les répertoires de sortie de cas (par exemple, pour libérer de l'espace disque), les répertoires d'index Solr situés dans SOLR_DATA_HOME doivent également être supprimés manuellement.
L'index de texte pour un cas d'Autopsy suivra une structure de nommage selon les règles suivantes: "[nom du cas Autopsy] [Horodatage de la création du cas] [Horodatage de la création de l'index] [shardX_replica_nY]". Par exemple, l'index de texte pour un cas d'Autopsy "Test Case" sera situé dans le répertoire suivant à l'intérieur SOLR_DATA_HOME:

Installation du service Windows Solr
À ce stade, Solr a été configuré et est prêt à l'emploi. La dernière étape consiste à le configurer en tant que service Windows afin qu'il démarre à chaque démarrage de l'ordinateur.
Ouvrez un invite de commande en tant qu'administrateur et accédez au répertoire "C:\solr-8.6.3\bin". À partir de là, exécutez la commande suivante: "nssm install Solr_8.6.3".
Une fenêtre d'interface utilisateur NSSM apparaîtra. Cliquez sur le bouton de navigation "Path":
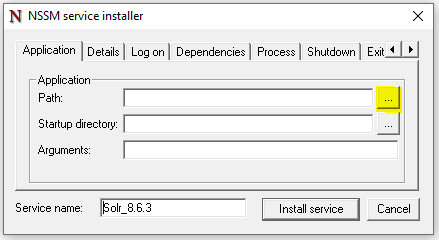
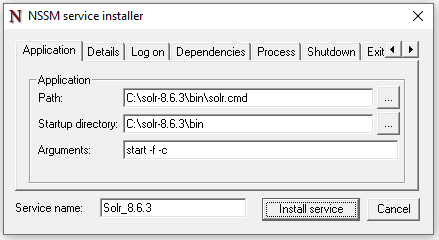
Selectionnez le fichier "C:\solr-8.6.3\bin\solr.cmd". REMARQUE: Assurez-vous de ne pas sélectionner le fichier "solr.in.cmd" par accident. Dans le paramètre "Arguments", tapez "start –f –c":
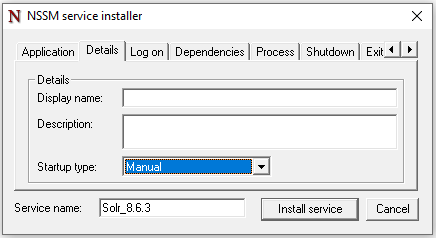
En option, configurez le nom d'affichage du service, le type de démarrage et les informations de compte:
Configurer l'utilisateur du service
Dans la section Choisissez vos comptes utilisateurs, vous avez dû décider sous quel utilisateur exécuter Solr. Pour configurer Solr afin qu'il s'exécute en tant que cet utilisateur, vous utiliserez Windows Service Manager.
Basculez vers l'onglet "Log On" pour modifier les informations d'identification de connexion pour l'utilisateur choisi qui aura accès au stockage partagé.
-
Si vous spécifiez un compte de domaine, le nom du compte sera sous la forme
"DOMAINNAME\username"comme le montre l'exemple ci-dessous

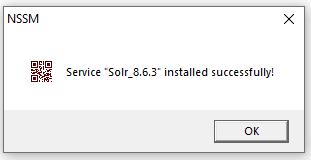
Cliquez sur "Install Service". Vous devriez voir apparaître la fenêtre d'interface utilisateur suivante:
Démarrer le service Solr
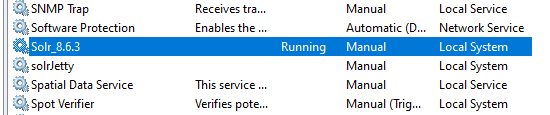
À ce stade, le service Solr a été configuré et est installé. Vous pouvez le vérifier en ouvrant la fenêtre "Services" de Windows:

Démarrez le service "Solr_8.6.3" et vérifiez que l'état du service passe à "En cours d'exécution".
Essais
Vous devez effectuer deux tests pour confirmer que la machine Solr est correctement configurée.
-
Interface Web: Vous devez essayer d'accéder au panneau d'administration de Solr dans un navigateur Web. Sur la machine Solr, accédez à http://localhost:8983/solr/#/ et vérifiez que la console d'administration Solr s'affiche. Vous devez également essayer d'accéder au panneau d'administration Solr dans un navigateur Web à partir d'une autre machine du réseau. Remplacez "localhost" dans l'URL précédente par l'adresse IP ou le nom d'hôte sur lequel le service Solr s'exécute.

Si le service est correctement démarré mais que vous ne pouvez pas voir la capture d'écran ci-dessus, il se peut que le port 8983 pour Solr et le port 9983 pour ZooKeeper soient bloqués par votre pare-feu. Contactez votre administrateur réseau pour ouvrir ces ports.
- Stockage partagé: Connectez-vous à l'ordinateur Solr en tant qu'utilisateur avec lequel vous avez décidé d'exécuter le service Solr et essayez d'accéder aux chemins de stockage partagé. Assurez-vous que vous pouvez accéder aux chemins UNC (ou aux lettres de lecteur si vous avez un NAS matériel). Si tout est configuré correctement, vous devriez pouvoir accéder aux chemins de stockage sans avoir à fournir d'informations d'identification. Si vous êtes invité à saisir un mot de passe pour accéder au stockage partagé, saisissez le mot de passe et choisissez d'enregistrer les informations d'identification ou modifiez la configuration afin que les mêmes mots de passe soient utilisés. Voir la rubrique Stockage des informations d'identification concernant les étapes de stockage des informations d'identification. Si vous avez besoin de stocker les informations d'identification, vous devez redémarrer le service ou redémarrer l'ordinateur (nous avons observé qu'un service en cours d'exécution n'obtient pas les informations d'identification mises à jour).
Configuration des clients Autopsy
Une fois les services configuré, vous allez configurer Autopsy pour activer les cas multi-utilisateurs. Pour le serveur Solr 8, configurez le service Solr 8 et les informations de connexion du service ZooKeeper. Les informations de connexion ZooKeeper sont requises. Le numéro de port ZooKeeper est égal au numéro de port du service Solr plus 1000. Par défaut, le port du service Solr est 8983, ce qui rend le port intégré à ZooKeeper égal à 9983. Vous pouvez également utiliser un service autonome ZooKeeper.
Ajout de plus de nœuds Solr (SolrCloud)
Solr 8 permet à plusieurs nœuds Solr de fonctionner ensemble en tant que cluster Solr. Dans ce mode (mode SolrCloud), chaque collection/index Solr est réparti sur tous les nœuds Solr disponibles. C'est ce qu'on appelle le sharding. Par exemple, s'il y a 4 nœuds Solr dans un cluster SolrCloud, l'index de texte sera divisé entre les 4 nœuds Solr, réduisant ainsi considérablement la charge sur chaque serveur Solr individuel et améliorant les performances d'indexation et de recherche Solr.
Pour créer un cluster Solr, vous devez suivre les étapes suivantes:
- Suivez les étapes des sections Configuration de Solr et Installation du service Windows Solr pour créer un nœud Solr (par exemple "Solr1"). Démarrez le service Solr sur la machine Solr1. Cette machine hébergera le service ZooKeeper pour le cluster SolrCloud.
- Pour ajouter un nœud Solr supplémentaire (par exemple "Solr2") au cluster SolrCloud, suivez les étapes des sections Configuration de Solr et Installation du service Windows Solr sur la machine Solr2. Ne démarrez pas encore le service Solr sur Solr2.
-
Solr utilise ZooKeeper pour sa coordination interne, donc tous les nœuds Solr dans le SolrCloud doivent pointer vers la même instance du service ZooKeeper. Par conséquent, pour que le nœud Solr2 fasse partie de SolrCloud, il doit utiliser le service ZooKeeper que tous les autres nœuds Solr du cluster SolrCloud utilisent. À l'étape 1, nous avons configuré le nœud Solr1 pour démarrer son service ZooKeeper intégré (il s'agit du comportement par défaut de Solr). Pour y parvenir, le paramètre ZK_HOST sur Solr2 doit être modifié pour pointer vers le service ZooKeeper qui s'exécute sur le nœud Solr1. Le numéro de port ZooKeeper est égal à SOLR_PORT plus 1000. Par défaut, SOLR_PORT est égal à 8983, donc le port ZooKeeper intégré est 9983. Par conséquent, le paramètre ZK_HOST dans le fichier
"C:\solr-8.6.3\bin\solr.in.cmd"(en supposant que le package Solr ZIP a été extrait dans le répertoire"C:\solr-8.6.3\") sur la machine Solr2 doit être modifié pour que le service ZooKeeper utilisé soit exécuté sur Solr1:9983.
- Démarrez le service Solr sur la machine Solr2.
-
Lorsque vous vous connectez à une console d'administration Solr sur Solr1 ou Solr2 (soit en allant sur http://localhost:8983/solr/#/ sur la machine, soit via http://solr1:8983/solr/#/), puis naviguez jusqu'à la section "Cloud" -> "Nodes" de l'arborescence d'administration, vous devriez voir tous les nœuds Solr qui font partie du SolrCloud:
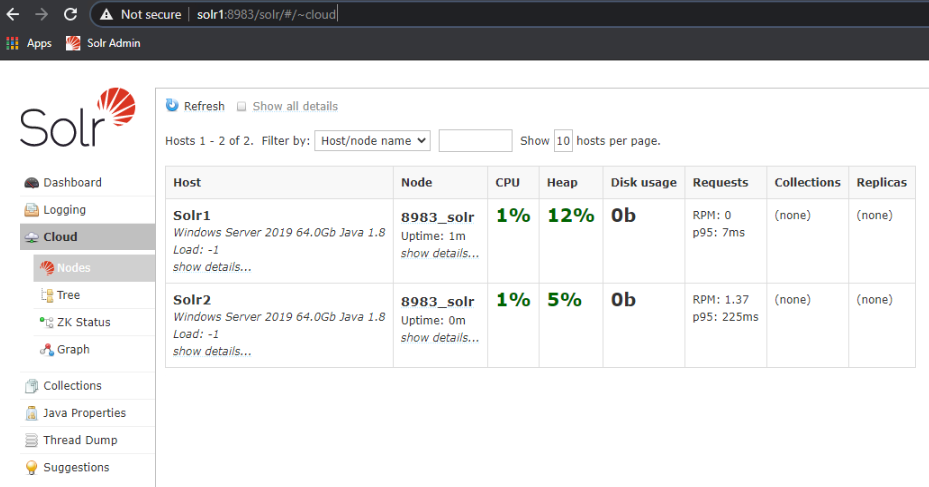
- Des nœuds Solr supplémentaires peuvent être ajoutés au SolrCloud en répétant les étapes précédentes.
Utilisation du service ZooKeeper par Autopsy
Autopsy utilise le service ZooKeeper à des fins de coordination multi-utilisateurs. Autopsy utilise ZooKeeper pour verouiller les ressources d'un cas avant de les modifier. Plus important encore, Autopsy stocke certaines de ses données d'état internes dans ZooKeeper - quels cas ont été créés, leur état de traitement (en attente, en traitement ou terminé), ainsi que d'autres données d'état des cas et des tâches. Ceci est particulièrement important si vous exécutez Autopsy en mode "Auto Ingest", car l'acquisition automatisée doit savoir quelles tâches ont déjà été traitées.
Dans la capture d'écran ci-dessous, Autopsy utilisera le serveur ZooKeeper qui s'exécute sur le serveur Solr 8 (machine "Solr1") à des fins de coordination.
Serveur ZooKeeper autonome
Lors de nos tests, il n'a pas été nécessaire d'avoir un serveur ZooKeeper autonome avec Autopsy. En cas d'utilisation normale d'Autopsy, il suffit d'utiliser le service ZooKeeper "intégré" qui est démarré par le service Solr (sur le port 9983). Cependant, la documentation d'Apache Solr recommande d'utiliser un service ZooKeeper autonome (s'exécutant sur une machine distincte) dans les environnements de production. Vous trouverez ci-dessous des instructions sur la configuration d'un serveur ZooKeeper autonome et la configuration de Solr et d'Autopsy pour utiliser ce serveur.
Les étapes générales pour mettre en place ce processus lié à Solr sont décrites dans le guide de l'utilisateur de Solr ci-dessous, dans la section "SolrCloud Configuration and Parameters":
https://lucene.apache.org/solr/guide/8_6/solrcloud-configuration-and-parameters.html
-
Téléchargez l'installation appropriée de ZooKeeper à partir de http://zookeeper.apache.org/releases.html . Solr 8.6.3 est intégré à Zookeeper 3.5.7. Il existe plusieurs options de téléchargement – binaires ou code source. Le fichier que vous recherchez est
"apache-zookeeper-3.5.7-bin.tar.gz": https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/ - Extrayez le fichier tar téléchargé contenant l'installation de ZooKeeper
-
Créer/éditer le fichier
"/conf/zoo.cfg"pour avoir les éléments suivants:- Spécifiez le répertoire "dataDir" - c'est là que la base de données ZooKeeper sera stockée.
- Spécifiez "clientPort". Par exemple, "clientPort=9983".
- "Four letter commands" doit être activé dans le fichier de configuration ZooKeeper: https://lucene.apache.org/solr/guide/8_6/setting-up-an-external-zookeeper-ensemble.html#configuration-for-a-zookeeper-ensemble
-
Il existe des scripts de démarrage Windows et Linux pour ZooKeeper. Pour Windows, ouvrez une invite de commande (administrateur NON requis), accédez au répertoire où le fichier tar a été extrait (par exemple,
"C:\Bitnami\zookeeper-3.5.7"), et tapez"bin\zkServer.cmd". Nous avons utilisé Cygwin dans nos tests et nous avons donc utilisé des commandes Linux dans nos exemples. Pour Linux/CygWin, allez dans le même répertoire (par ex."C:\Bitnami\zookeeper-3.5.7"), et tapez"bin/zkServer.sh start". -
Pour vérifier que ZooKeeper est en cours d'exécution, dans l'invite de commande, vous pouvez taper
"bin/zkServer.sh status"(ou une commande Windows équivalente).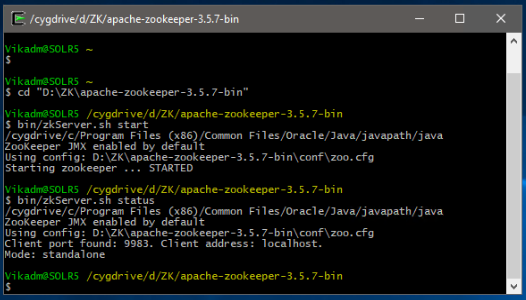
-
Pour que Solr utilise un ZooKeeper autonome, les étapes suivantes doivent être effectuées. Accédez au répertoire où se trouvent les scripts de démarrage Solr (généralement
"C:\solr-8.6.3\apache-solr\bin"). Ouvrez le fichier"solr.in.cmd"dans un éditeur de texte. Si le service ZooKeeper autonome s'exécute sur la même machine (non recommandé), modifiez la variable ZK_HOST en"set ZK_HOST=localhost:9983". Si ZooKeeper s'exécute sur une machine différente (par exemple, "Solr5"), entrez le nom d'hôte ou l'adresse IP de la machine ZooKeeper au lieu de "localhost" (par exemple,"set ZK_HOST=Solr5:9983").
- La réinstallation du service Solr n'est pas nécessaire. Arrêtez simplement le service Solr et redémarrez-le.
-
Une fois le service Solr redémarré, vous pouvez accéder à la console d'administration Solr (Cloud -> ZK Status) et vérifiez que Solr utilise le bon ZooKeeper et que ZooKeeper est en cours d'exécution.

-
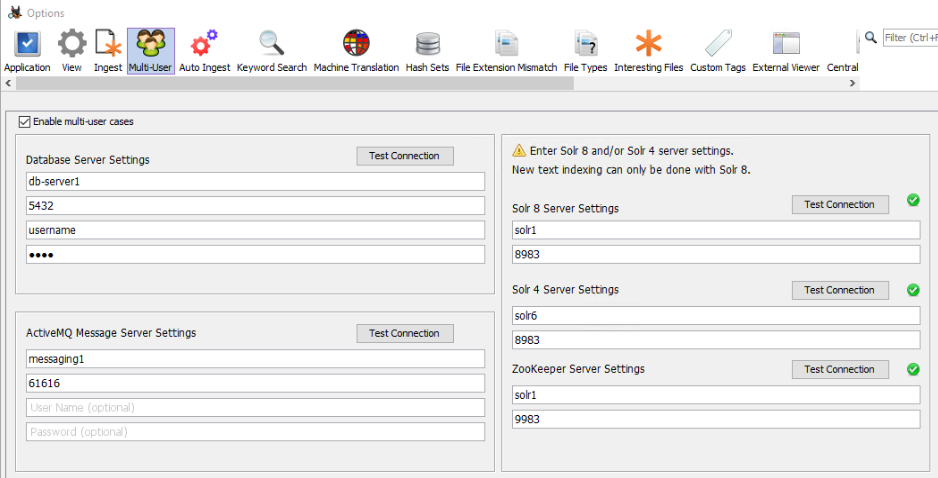
Configurez les options multi-utilisateurs d'Autopsy pour utiliser le serveur autonome ZooKeeper. Démarrez Autopsy et ouvrez le panneau des paramètres multi-utilisateurs à partir de "Tools", "Options", "Multi-user". Notez que pour créer ou ouvrir des cas multi-utilisateurs, "Enable Multi-user cases" doit être coché et les paramètres ci-dessous doivent être corrects.

Sauvegarde
Solr crée deux types de données qui doivent être sauvegardées:
- Index de texte: Ceux-ci sont stockés dans le répertoire qui a été spécifié dans le paramètre SOLR_DATA_HOME (voir Paramètres de configuration Solr).
-
Données ZooKeeper: Autopsy utilise un service appelé ZooKeeper intégré à Solr qui stocke des données sur les cas existants et sur qui les a ouverts. Ces données doivent être sauvegardées afin que vous puissiez avoir une liste de tous les cas multi-utilisateurs disponibles.
-
Dans une installation par défaut les données sont stockées dans
"C:\solr-8.6.3\server\solr zoo_data"(en supposant que le package ZIP de Solr ait été extrait dans le répertoire"C:\solr-8.6.3").
-
Dans une installation par défaut les données sont stockées dans
Dépannage / Optimisation des performances
Problèmes de démarrage retardé avec un grand nombre de collections Solr
Lors de nos tests, nous avons rencontré des problèmes lorsqu'un très grand nombre (des milliers) de cas Autopsy multi-utilisateurs ont été créés. Chaque nouveau cas multi-utilisateurs Autopsy crée une "collection" Solr qui contient l'index de texte Solr. Avec 2 000 collections existantes, lorsque le service Solr est redémarré, Solr semble "charger" en interne environ 250 collections par minute (par ordre chronologique, en commençant par les collections les plus anciennes). Après 4 minutes, environ la moitié des 2 000 collections étaient chargées. Les utilisateurs peuvent rechercher dans les collections qui ont été chargées, mais ils ne peuvent pas ouvrir ou rechercher dans les collections qui n'ont pas encore été chargées en interne par Solr. Après 7 à 8 minutes, toutes les collections ont été chargées. Ces chiffres varient en fonction de la configuration spécifique du cluster, de l'emplacement du fichier d'index de texte (stockage réseau ou local), du débit du réseau, du nombre de serveurs Solr, etc...
Utilisation du tas Solr et recommandations
Le tas JVM Solr joue un rôle particulièrement important si vous allez créer un grand nombre de cas Autopsy (c'est-à-dire des collections Solr). Voici quelques "règles empiriques" de statistiques d'utilisation du tas Solr que nous avons identifiées lors de nos tests internes:
- Pour les très petits cas/collections, nos tests montrent que Solr utilise un minimum absolu de 7 à 10 Mo de tas par collection.
- Pour les cas/collections plus volumineux (taille de E01 en entrée : 50-100 Go), Solr utilise au moins 65 Mo par collection
- Pour les cas/collections volumineux (taille de E01 en entrée : 1,5 To) Solr utilise au moins 850 Mo par collection
Dépannage des problèmes de tas Solr
Lorsque la JVM Solr a utilisé tout son tas disponible et est incapable de libérer de la mémoire avec des éliminations de collections, le service Solr ne pourra pas créer de nouvelles collections ou peut complètement ne plus répondre, ce qui empêchera Autopsy de créer de nouveaux index de texte. Vous trouverez ci-dessous une liste de certaines erreurs que vous pourriez voir à la suite de ce problème dans les journaux de service Solr (pas dans les journaux d'Autopsy) et/ou la console d'administration Solr:
- org.apache.solr.common.SolrException: Could not register as the leader because creating the ephemeral registration node in ZooKeeper failed
- RequestHandlerBase org.apache.solr.common.SolrException: Failed to get config from zookeeper
- RecoveryStrategy Error while trying to recover. org.apache.solr.common.SolrException: Cloud state still says we are leader.
- RequestHandlerBase org.apache.solr.common.SolrException: Could not load collection from ZK
- org.apache.solr.common.SolrException: Error CREATEing SolrCore: Unable to create core. Caused by: There are no more files
- org.apache.solr.common.SolrException: java.io.IOException: There are no more files
- org.apache.solr.common.SolrException: Cannot unload non-existent core
- ZkIndexSchemaReader Error creating ZooKeeper watch for the managed schema
Vous pouvez également voir les erreurs ZooKeeper suivantes:
- org.apache.zookeeper.KeeperException$NodeExistsException: KeeperErrorCode = NodeExists
- org.apache.zookeeper.KeeperException$BadVersionException: KeeperErrorCode = BadVersion for (collection_name)/state.json
- org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /roles.json
- org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /configs/AutopsyConfig/managed-schema
Le thème commun à la plupart de ces erreurs est la rupture de la communication entre Solr et ZooKeeper, en particulier lors de l'utilisation d'un serveur ZooKeeper intégré. Il est important de noter que ces erreurs peuvent potentiellement se produire pour d'autres raisons et ne sont pas propres aux problèmes de tas Solr.
Surveillance de l'utilisation du tas Solr
Le moyen le plus simple de voir l'utilisation actuelle du tas Solr est de consulter la page Web de la console d'administration Solr. Pour accéder à la console d'administration Solr, sur la machine Solr, accédez à http://localhost:8983/solr/#/ . Vous pourrez y voir l'utilisation de la mémoire Solr:
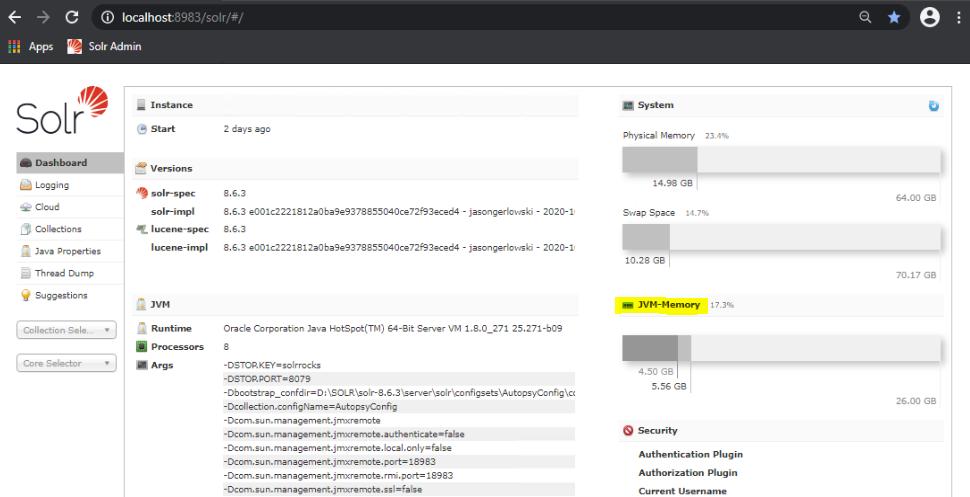
Cependant, le tableau de bord ne montre pas suffisamment de détails pour savoir quand Solr est à court de tas, il ne doit donc être utilisé que pour identifier que vous n'avez PAS de problèmes de tas. Même si le tableau de bord indique que le tas Solr est entièrement utilisé, cela peut être un problème ou non. Il est préférable d'utiliser des outils de profilage comme Java VisualVM. Pour que VisualVM se connecte à Solr, vous devez activer l'interface JMX pour le processus Java de Solr. Les détails sont décrits ici :
Le tas Solr et d'autres réglages de performances sont décrits dans l'article suivant:
Remarques sur le réglage des performances de Solr
Si vous envisagez de travailler avec des images volumineuses (de plusieurs To) et que les performances de KWS sont importantes, la meilleure approche consiste à utiliser un serveur Solr en réseau (multi-utilisateurs).
Quelques notes:
-
Un seul serveur Solr fonctionne bien pour les sources de données jusqu'à 1 To ; après cela, ses performances commencent à ralentir. Les performances ne "chutent pas", mais elles continuent de ralentir à mesure que vous ajoutez plus de données à l'index. Après 3 To de données d'entrée, les performances de Solr diminuent considérablement.
-
Un seul serveur Solr multi-utilisateur peut ne pas fonctionner beaucoup mieux qu'un cas Autopsy mono-utilisateur. Cependant, en mode multi-utilisateurs, vous pouvez ajouter des serveurs Solr supplémentaires et créer un cluster Solr. Voir la rubrique Ajout de plus de nœuds Solr (SolrCloud) dans la documentation ci-dessus. Ces nœuds supplémentaires sont une source des gains en performances, en particulier pour les sources de données d'entrée volumineuses. La documentation Apache Solr appelle ce mode "SolrCloud" et chaque serveur Solr est appelé un "shard". Plus vous avez de serveurs/shards Solr, meilleures sont les performances pour les grands ensembles de données. Sur nos clusters de test et de production, nous utilisons 4 à 6 serveurs Solr pour gérer des ensembles de données allant jusqu'à 10 To, ce qui semble être la limite la plus haute. Après cela, il vaut mieux diviser votre cas Autopsy en plusieurs cas, créant ainsi un index Solr distinct pour chaque cas.
-
Lors de nos tests, un SolrCloud à 3 nœuds indexe les données environ deux fois plus vite qu'un seul nœud Solr. Un SolrCloud à 6 nœuds indexe les données presque deux fois plus vite qu'un SolrCloud à 3 nœuds. Après cela, nous n'avons pas vu beaucoup de gain de performance. Ces chiffres de performances dépendent fortement du débit du réseau, des ressources de la machine, de la vitesse d'accès au disque et du type de données indexées.
-
Les recherches de correspondance exacte sont beaucoup plus rapides que les recherches de sous-chaîne ou d'expression régulière.
-
Les recherches Regex ont tendance à utiliser beaucoup de RAM sur le serveur Solr.
-
L'indexation/la recherche d'espace non alloué ralentit vraiment tout, car il s'agit principalement de données binaires ou tronquées.
-
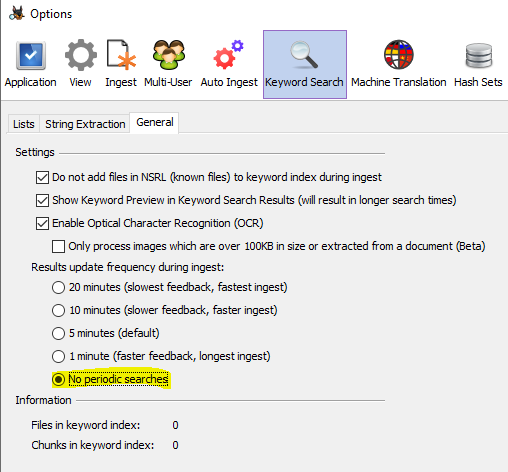
Si vous n'allez pas consulter les résultats de la recherche tant que l'acquisition n'est pas terminée, vous devez désactiver les recherches périodiques par mot-clé. Elles commenceront à prendre plus de temps au fur et à mesure que vos données d'entrée augmenteront. Cela peut être fait via le menu Tools->Options->Keyword Search:
-
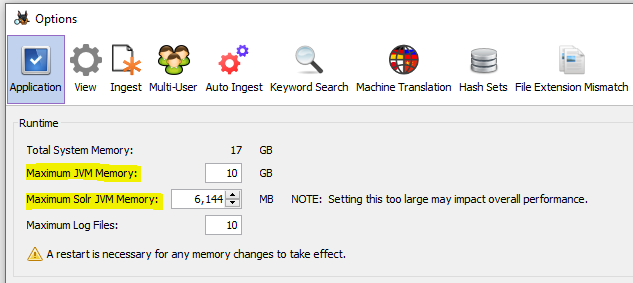
En mode mono-utilisateur, si vous exécutez une acquisition et indexez des sources de données de plusieurs To, la mémoire d'Autopsy et en particulier la mémoire JVM Solr doivent être augmentées par rapport aux paramètres par défaut. Cela peut être fait via le menu Tools->Options->Application. Nous recommandons une taille de tas d'au moins 10 Go pour Autopsy et une taille de tas d'au moins 6 à 8 Go pour Solr. Notez qu'il s'agit des valeurs "maximum" que le processus sera autorisé à utiliser/demander. Le système d'exploitation n'allouera pas plus de tas que le processus n'en a réellement besoin.
Réglage des opérations de validation du serveur Solr
Lorsque Autopsy s'exécute dans un environnement de cluster multi-utilisateurs avec plusieurs nœuds d'acquisition automatique, il peut être intéressant de régler la configuration des opérations de validation de Solr.
Solr a deux types de validations : les validations "dures" ("hard commits") et les validations "souples" ("soft commits"). Celles-ci sont expliquées en détail sur la page suivante: https://lucidworks.com/post/understanding-transaction-logs-softcommit-and-commit-in-sorlcloud/
En bref:
- Les validations "dures" transferent les documents nouvellement indexés de la RAM vers l'index Solr, sur le disque.
- En fonction de la configuration, les validations "dures" peuvent rendre les documents nouvellement indexés "visibles" ou non pour la recherche.
- Les validations "souples" ne transfèrent pas les documents nouvellement indexés sur le disque, mais ils les rendent "visibles" pour la recherche.
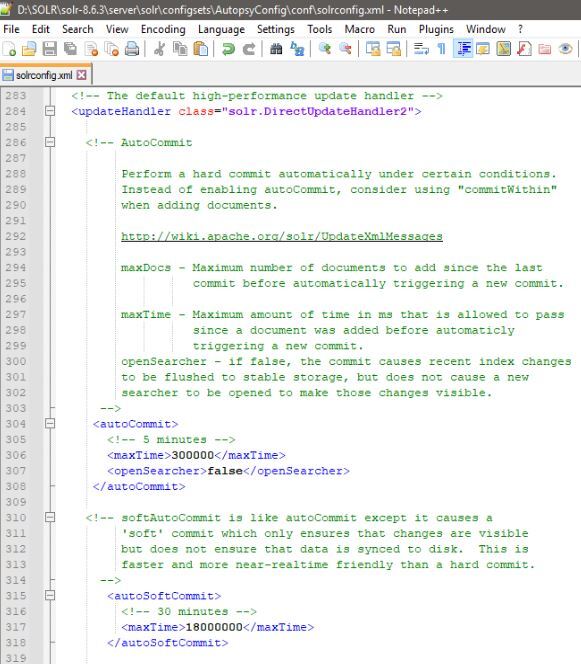
Par défaut (lors de l'utilisation d'AutopsyConfig), les serveurs Solr effectuent une validation "dure" toutes les 5 minutes et rendent également les documents nouvellement indexés "visibles" pour la recherche. Ces opérations peuvent être coûteuses en ressources lorsqu'elles sont effectuées sur un index volumineux situé sur un lecteur réseau partagé. Dans cette situation, il peut être très intéressant de modifier la configuration de Solr (située dans "REPERTOIRE_INSTALLATION_SOLR\server\solr\configsets\AutopsyConfig\conf\solrconfig.xml") avec les changements suivants :
- Modifiez les validations "dures" pour transférer systématiquement les documents nouvellement créés toutes les 5 minutes sans les rendre "visibles". Ceci peut être fixé en définissant "openSearcher" sur "false" dans la section "autoCommit" du fichier de configuration Solr.
- Activez les validations "souples" à effectuer toutes les 30 minutes, rendant ainsi les documents nouvellement indexés "visibles" pour une recherche toutes les 30 minutes. Ceci peut être fixé en activant la section "autoSoftCommit" du fichier de configuration Solr. L'inconvénient est que la recherche du dernier document peut prendre jusqu'à 30 minutes. Gardez à l'esprit que cela n'a d'incidence que dans le cas où un analyste recherche un dossier alors que l'acquisition est toujours en cours. Autopsy effectue automatiquement une validation une fois l'acquisition terminée afin que tous les documents soient immédiatement visibles à ce moment-là.
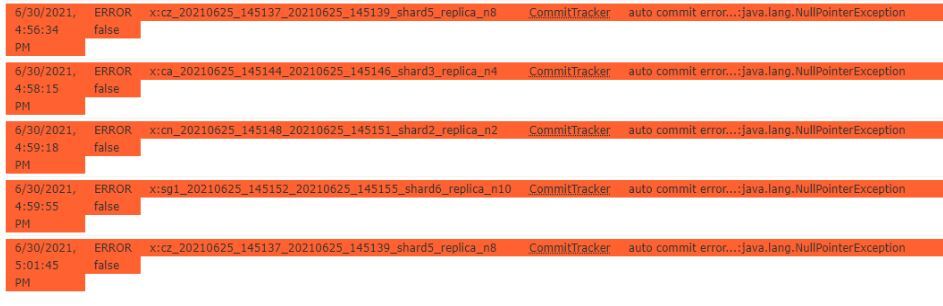
L'image suivante montre les modifications de configuration de Solr décrites ci-dessus:
Jusqu'à ce qu'une validation "dure" soit effectuée, par défaut Solr maintient également un journal des transactions qui contient le texte brut de chaque document nouvellement indexé depuis la dernière validation "dure". Lorsque l'index Solr est situé sur un partage réseau, cela peut à nouveau être une opération très coûteuse en ressources. Les journaux de transactions peuvent être désactivés en commentant la section "updateLog" du fichier de configuration Solr:
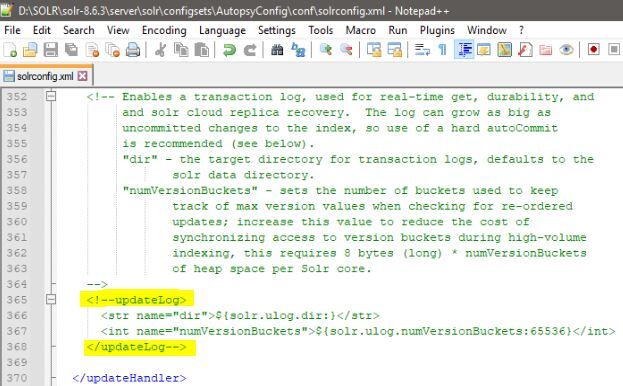
Notez bien cependant que cela a pour effet secondaire de créer des erreurs CommitTracker dans les journaux Solr et dans la console d'administration Solr. Ces erreurs peuvent être ignorées si le journal des transactions a été intentionnellement désactivé.