Table des matières
Qu'est ce que ça fait
Le module "Keyword Search" facilite à la fois la partie de recherche lors de l'acquisition et prend également en charge la recherche manuelle de texte une fois l'acquisition terminée (voir Recherche par mot-clé ad hoc). Il extrait le texte des fichiers en cours d'acquisition, des rapports sélectionnés générés et des résultats d'autres modules. Ce texte extrait est ensuite ajouté à un index Solr qui peut ensuite être consulté au cours de cette recherche.
Autopsy fait de son mieux pour extraire le maximum de texte des fichiers indexés. Tout d'abord, l'indexation essaiera d'extraire le texte des formats de fichier pris en charge, tels que le format de fichier texte brut, les documents MS Office, les fichiers PDF, les e-mails et bien d'autres. Si le fichier n'est pas pris en charge par l'extracteur de texte standard, Autopsy reviendra à un algorithme d'extraction de chaîne de caractères. L'extraction de chaînes de caractères sur des formats de fichiers inconnus ou sur des fichiers binaires arbitraires peut souvent extraire une quantité importante de texte d'un fichier, assez souvent pour fournir des indices supplémentaires aux analystes. L'extraction de chaînes de caractère n'extraira pas les chaînes de texte des fichiers chiffrés.
Autopsy est livrée avec des listes intégrées qui définissent des expressions régulières et permettent à l'utilisateur de rechercher des numéros de téléphone ("Phone Numbers"), des adresses IP ("IP addresses"), des URL ("URLs") et des adresses e-mail ("E-mail addresses"). Cependant, l'activation de certaines de ces listes très générales peut produire un très grand nombre de résultats, et beaucoup d'entre eux peuvent être des faux positifs. Les expressions régulières peuvent prendre du temps à se terminer.
Une fois les fichiers placés dans l'index Solr, ils peuvent être recherchés rapidement pour des mots-clés spécifiques, des expressions régulières ou des listes de recherche de mots-clés pouvant contenir un mélange de mots-clés et d'expressions régulières. Les requêtes de recherche peuvent être exécutées automatiquement pendant l'exécution de l'acquisition ou à la fin de l'acquisition, en fonction des paramètres actuels et du temps nécessaire à l'acquisition de l'image.
Référez vous à la page Recherche par mot-clé ad hoc pour plus de détails sur la spécification des expressions régulières et d'autres types de recherche.
Configuration de la recherche par mot-clé
L'option de configuration de la recherche par mot-clé ("Keyword Search") comporte trois onglets, chacun ayant son propre objectif:
- L'Onglet "Lists" est utilisé pour ajouter, supprimer et modifier des listes de recherche par mot-clé.
- L'Onglet "String Extraction" est utilisé pour activer les scripts de langage et le type d'extraction.
- L'Onglet "General" est utilisé pour configurer les horaires d'acquisition et afficher les informations.
Onglet "Lists"
L'onglet "Lists" est utilisé pour créer/importer et ajouter du contenu aux listes de mots clés. Pour créer une liste, sélectionnez le bouton "New List" et choisissez un nom pour la nouvelle liste de mots clés. Une fois la liste créée, des mots clés peuvent y être ajoutés (voir la section Créer des mots-clés pour plus d'informations sur les types de mots-clés). Des listes peuvent être ajoutées au processus d'acquisition de la recherche par mot-clé; les recherches auront lieu à intervalles réguliers au fur et à mesure que le contenu est ajouté à l'index.
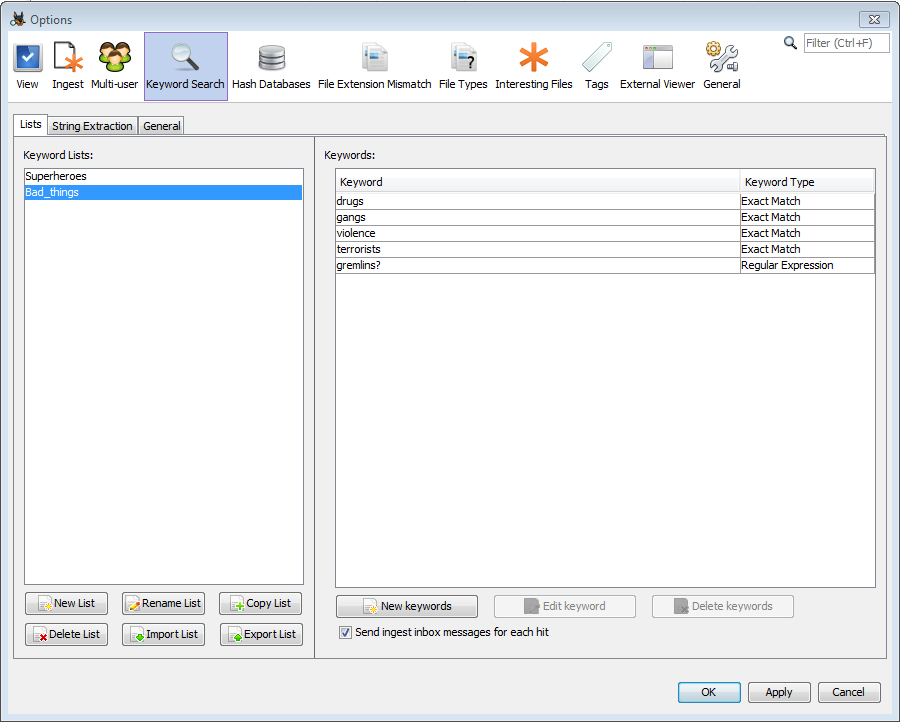
Les listes de mots-clés se trouvent sur le côté gauche du panneau. De nouvelles listes peuvent être créées, les listes existantes peuvent être renommées, copiées, exportées ou supprimées et les listes peuvent être importées. Autopsy prend en charge l'importation de listes Encase délimitées par des tabulations ainsi que des listes créées précédemment avec Autopsy. Pour les listes Encase, la structure et la hiérarchie des dossiers sont ignorées. Il n'existe actuellement aucun moyen d'exporter des listes à utiliser avec Encase, mais les listes peuvent être exportées pour être partagées entre les utilisateurs d'Autopsy.
Une fois qu'une liste de mots-clés est sélectionnée, tous les mots-clés de cette liste seront affichés sur le côté droit de l'onglet. Le bouton "New Keywords" peut être utilisé pour ajouter une ou plusieurs entrées à la liste, et les boutons "Edit keyword" et "Delete keywords" peuvent modifier les entrées existantes.
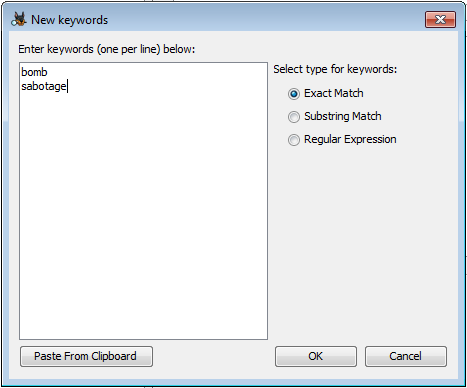
Les nouvelles entrées peuvent être saisies dans la boîte de dialogue ou collées à partir du presse-papiers. Toutes les entrées ajoutées en même temps doivent être du même type de correspondance ("Exact Match": correspondance exacte, "Substring Match" : correspondance avec une sous-chaîne de caractères, ou "Regular Expression" : expression régulière), mais la boîte de dialogue peut être utilisée plusieurs fois pour ajouter des mots-clés à la liste. Reportez-vous à la section Créer des mots-clés pour une explication sur chaque type de mot-clé.
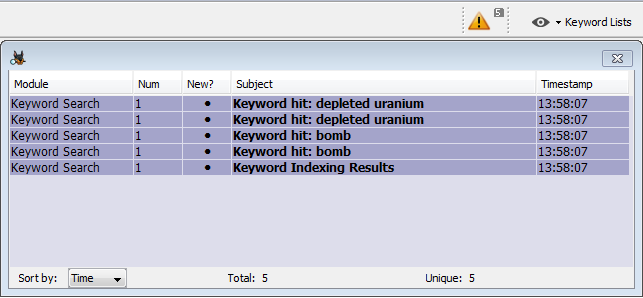
Sous la liste "Keywords", vous pouvez solliciter la réception d'un messages dans la boite de notification des Ingest Modules pour chaque découverte de correspondance. Si cette option est activée, la découverte de chaque mot-clé trouvé pour cette liste sera notifiée via le triangle jaune à côté du bouton "Keyword Lists". Cette fonctionnalité vous offre un moyen rapide d'afficher les résultats de recherche de mots clés les plus importants.
Onglet "String Extraction"
Le paramètre "String Extraction" définit comment les chaînes de caractères sont extraites des fichiers dont le texte ne peut pas être extrait normalement car les formats de ces fichier ne sont pas pris en charge. C'est le cas des fichiers binaires arbitraires (tels que les fichiers d'échanges) et des morceaux d'espace non alloué qui représentent des fichiers supprimés. Lorsque nous extrayons des chaînes de caractères de fichiers binaires, nous devons interpréter les séquences d'octets comme du texte différemment en fonction du codage de texte possible et du script/langage utilisé. Dans de nombreux cas, nous ne savons pas à l'avance dans quel encodage/langue spécifique le texte est encodé. Cependant, cela peut être intéressant si l'enquêteur recherche une langue spécifique, car en sélectionnant moins de langues, les performances d'indexation seront améliorées et le nombre des faux positifs seront réduits.
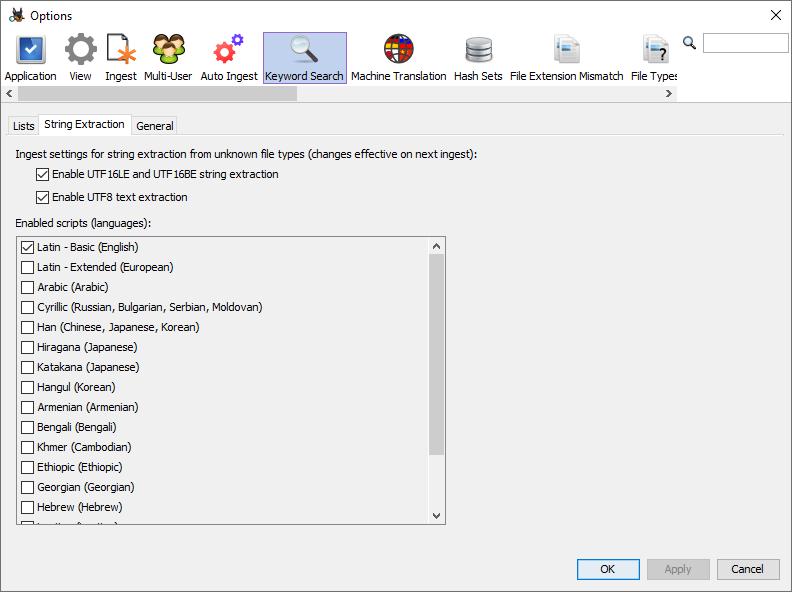
Le paramètre par défaut consiste à rechercher uniquement les chaînes anglaises, codées en UTF8 ou UTF16. Ce paramètre offre les meilleures performances (temps d'acquisition le plus court). L'utilisateur peut également utiliser en premier le "String Viewer" et essayer différents paramètres de script/langue, et voir quels paramètres donnent des résultats satisfaisants pour le type de texte pertinent pour l'enquête. Ensuite, ce même paramètre qui fonctionne pour l'enquête peut être appliqué au module d'acquisition de recherche par mot-clé.
Onglet "General"
Prise en charge du NIST NSRL
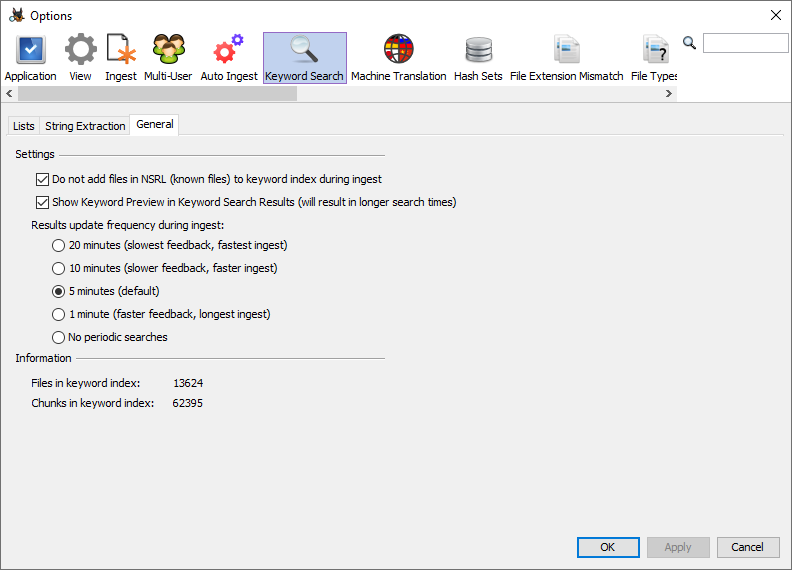
Le module d'acquisition "Hash Lookup" peut être configuré pour utiliser l'ensemble de hachage NIST NSRL de fichiers connus. L'onglet "General" de la boîte de dialogue de configuration avancée de la recherche par mot-clé contient une option permettant d'ignorer l'indexation par mot-clé et de rechercher des fichiers précédemment marqués comme "connus" ("Known") et sans intérêt. La sélection de cette option peut réduire considérablement la taille de l'index et améliorer les performances d'acquisition. Dans la plupart des cas, l'utilisateur n'a pas besoin de rechercher par mot-clé les fichiers "connus".
Fréquence de mise à jour des résultats lors de l'acquisition
Pour contrôler la fréquence à laquelle les recherches sont exécutées pendant l'acquisition, l'utilisateur peut ajuster le paramètre de synchronisation disponible dans l'onglet "General" de la boîte de dialogue de configuration avancée de la recherche par mot-clé. La réduction du nombre de minutes entraînera des mises à jour d'index et des recherches plus fréquentes et l'utilisateur pourra voir les résultats davantage en temps réel. Cependant, des mises à jour plus fréquentes peuvent affecter les performances globales, en particulier sur les systèmes peu performants, et peuvent potentiellement allonger le temps total nécessaire à l'acquisition.
On peut également choisir de ne pas effectuer de recherches périodiques. Cela accélérera l'acquisition. Les utilisateurs qui choisissent cette option peuvent exécuter leurs recherches par mots-clés une fois que l'index de recherche par mots-clés est complet.
Utilisation du module
Les recherche peuvent être exécutées manuellement par l'utilisateur à tout moment, tant qu'il existe des fichiers déjà indexés et prêts à être analysés. Une recherche effectuée avant la fin de l'indexation ne s'exécutera naturellement que les index déjà compilés.
Voir la page sur les Ingest Modules pour plus d'information sur les modules d'acquisition en général.
Une fois qu'il y a des fichiers dans l'index, la Recherche par mot-clé ad hoc sera disponible pour une recherche manuelle à tout moment.
Paramétrages
Les options de paramétrages du module de recherches par mots clés permettent à l'utilisateur d'activer ou de désactiver les expressions de recherche intégrées spécifiques : Phone Numbers (numéros de téléphone), IP Addresses (adresses IP), Email Addresses (adresses mail), et URLs. En utilisant le bouton "Global Settings" (expliqué ci-dessous), on peut ajouter des ensembles de mots clés personnalisés.
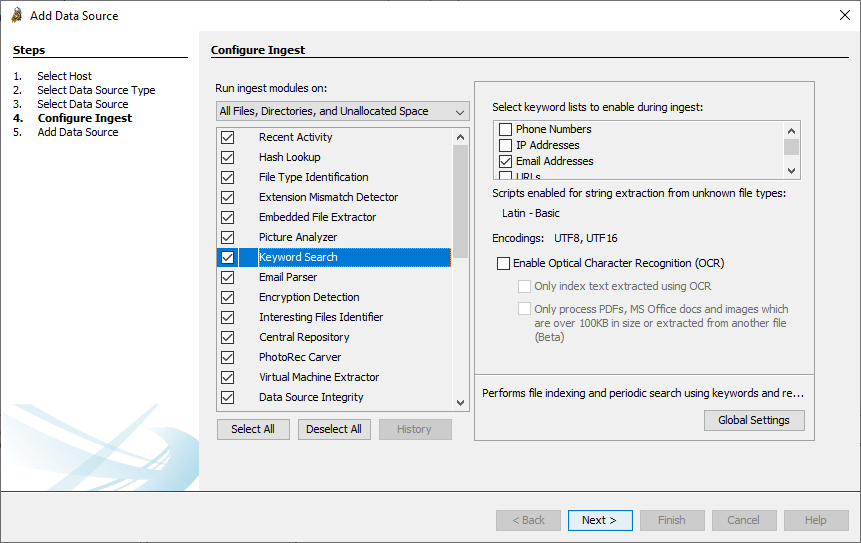
Optical Character Recognition (reconnaissance optique de caractères)
Il y a aussi un paramètre pour activer la reconnaissance optique de caractères (ou Optical Character Recognition - OCR). S'il est activé, le texte peut être extrait des types d'images pris en charge. L'activation de cette fonctionnalité rendra l'exécution du module de recherche par mot-clé plus longue et les résultats pourront ne pas être parfaits.
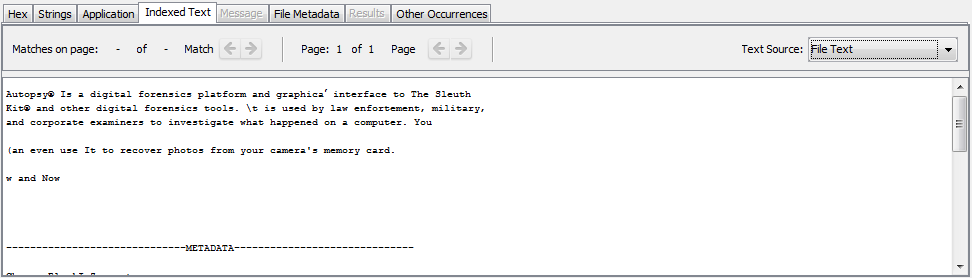
Voici un exemple d'image contenant du texte:
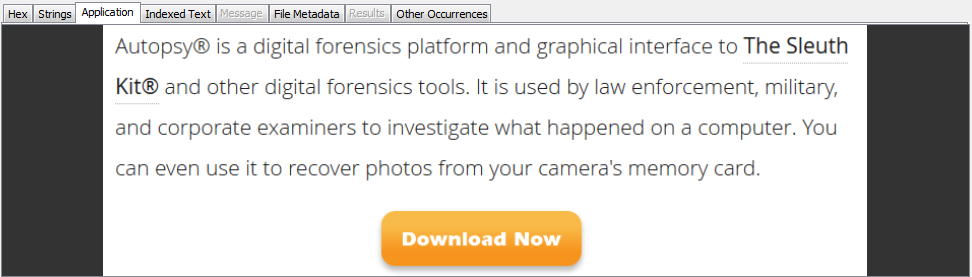
L'onglet "Indexed Text" affiche les résultats lors de l'exécution du module de recherche par mot-clé avec l'option OCR activée. Si nous devions utiliser la recherche par mot-clé pour rechercher le mot "forensics", ce fichier serait une correspondance.
Les deux options liées à l'OCR sont les suivantes:
- Only index text extracted using OCR. Cela n'indexera que le texte détecté par l'OCR et empêchera l'indexation de texte trouvé dans les fichiers texte, les documents, etc...
- Only process PDFs, MS Office docs and images which are over 100KB in size or extracted from another file. Avec cette option sélectionnée, l'OCR ne sera effectuée que sur les images de plus de 100 Ko et les documents PDF/Office. Il fonctionnera également sur des images de toute taille extraites d'un autre fichier.
Par défaut, l'OCR n'est configuré que pour le texte anglais. Sa configuration dépend de la présence de fichiers de langue (appelés fichiers "traineddata") qui existent dans un endroit qu'Autopsy peut atteindre. Pour ajouter la prise en charge de plusieurs langues, vous devrez télécharger des "traineddata" supplémentaires et les déplacer au bon endroit. Les étapes suivantes décrivent ce processus:
- Aller sur https://tesseract-ocr.github.io/tessdoc/Data-Files.
- Dans la section intitulée "Data Files for Version 4.00 (November 29, 2016)", vous trouverez un tableau contenant des fichiers représentant chaque langue. Ces fichiers ont l'extension ".traineddata".
- Pour télécharger la langue souhaitée, cliquez sur les liens dans la colonne à l'extrême droite du tableau. Vous pouvez en télécharger autant que vous le souhaitez. Notez que vous ne devez choisir que dans ce tableau. Les fichiers de langue dans les autres sections ne sont pas garantis de fonctionner dans Autopsy.
- Une fois que vous avez téléchargé vos fichiers de langue, faites-les simplement glisser et déposez-les dans le dossier "AppData\Roaming\autopsy\ocr_language_packs" se trouvant dans votre dossier utilisateur.
- Démarrez Autopsy et vous serez prêt. Si Autopsy était en cours d'exécution, cela nécessitera un redémarrage pour prendre effet.
Les fichiers de langue seront désormais pris en charge lorsque l'OCR est activé dans les paramètres de "Keyword Search".
Voir les résultats
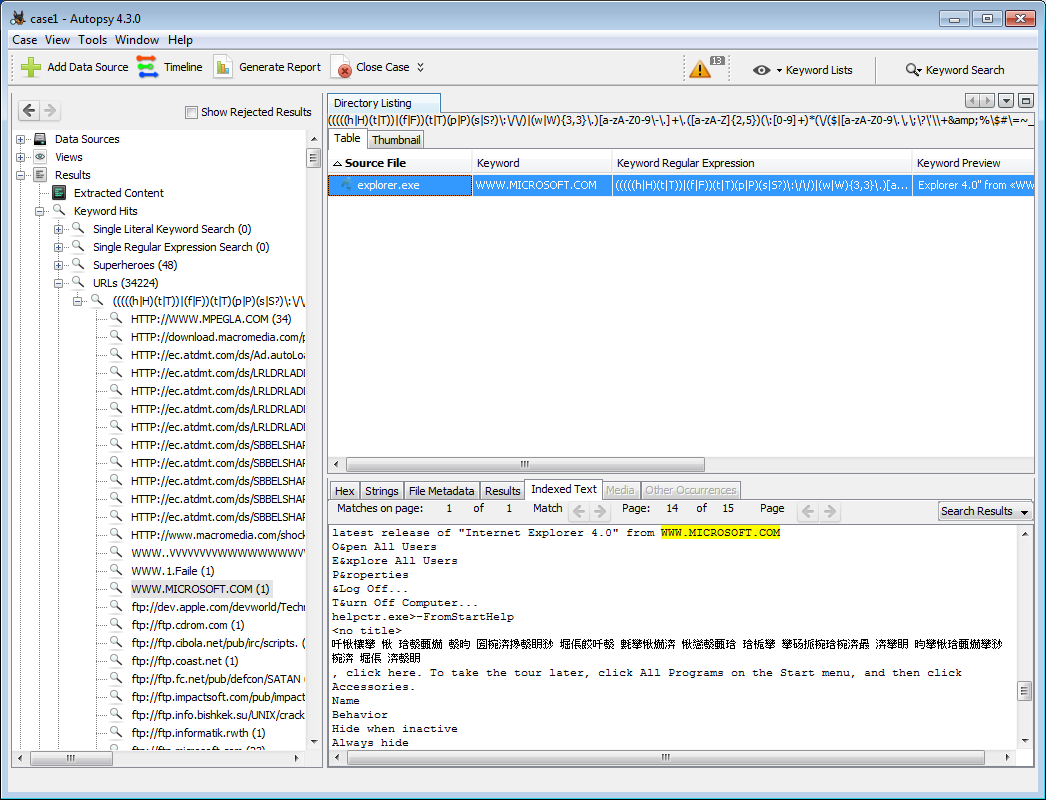
Le module "Keyword Search" enregistrera les résultats de la recherche, que celle-ci ait été effectuée par le processus d'acquisition ou manuellement par l'utilisateur. Les résultats enregistrés sont disponibles dans l'arborescence des répertoires dans le panneau de gauche.
Les résultats des mots clés apparaîtront dans l'arborescence sous "Keyword Hits". Chaque terme de recherche par mot-clé affichera le nombre de correspondances et peut être développé pour afficher ces correspondances. À partir de là, en cliquant sur l'une des correspondances, une liste de fichiers apparaîtra sur le côté droit de l'écran. Sélectionnez un fichier et accédez à l'onglet "Indexed Text" pour voir exactement où les correspondances apparaissent dans le fichier.